How LLMs Learn from the Internet: The Training Process
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Byte-pair encoding
7 min read
The article specifically mentions Byte Pair Encoding as the tokenization method LLMs use, but doesn't explain how this compression algorithm works. Understanding BPE's origins in data compression and its adaptation for NLP would give readers deeper insight into why LLMs break words into subword units.
-
Backpropagation
13 min read
The article discusses how parameters are 'tuned during training' and mentions gradient descent conceptually, but doesn't explain the fundamental algorithm that makes neural network learning possible. Backpropagation is the mathematical process that enables LLMs to adjust their billions of parameters.
-
Perceptron
11 min read
The article describes LLMs as 'extraordinarily sophisticated pattern recognition systems' with billions of parameters acting as weights. The perceptron, invented by Frank Rosenblatt in 1958, was the first trainable neural network and establishes the historical foundation for understanding how weighted connections learn patterns—the basic building block that modern LLMs scale up massively.
Is your team building or scaling AI agents?(Sponsored)

One of AI’s biggest challenges today is memory—how agents retain, recall, and remember over time. Without it, even the best models struggle with context loss, inconsistency, and limited scalability.
This new O’Reilly + Redis report breaks down why memory is the foundation of scalable AI systems and how real-time architectures make it possible.
Inside the report:
The role of short-term, long-term, and persistent memory in agent performance
Frameworks like LangGraph, Mem0, and Redis
Architectural patterns for faster, more reliable, context-aware systems
The first time most people interact with a modern AI assistant like ChatGPT or Claude, there’s often a moment of genuine surprise. The system doesn’t just spit out canned responses or perform simple keyword matching. It writes essays, debugs code, explains complex concepts, and engages in conversations that feel remarkably natural.
The immediate question becomes: how does this actually work? What’s happening under the hood that enables a computer program to understand and generate human-like text?
The answer lies in a training process that transforms vast quantities of internet text into something called a Large Language Model, or LLM. Despite the almost magical appearance of their capabilities, these models don’t think, reason, or understand like human beings. Instead, they’re extraordinarily sophisticated pattern recognition systems that have learned the statistical structure of human language by processing billions of examples.
In this article, we will walk through the complete journey of how LLMs are trained, from the initial collection of raw data to the final conversational assistant. We’ll explore how these models learn, what their architecture looks like, the mathematical processes that drive their training, and the challenges involved in ensuring they learn appropriately rather than simply memorizing their training data.
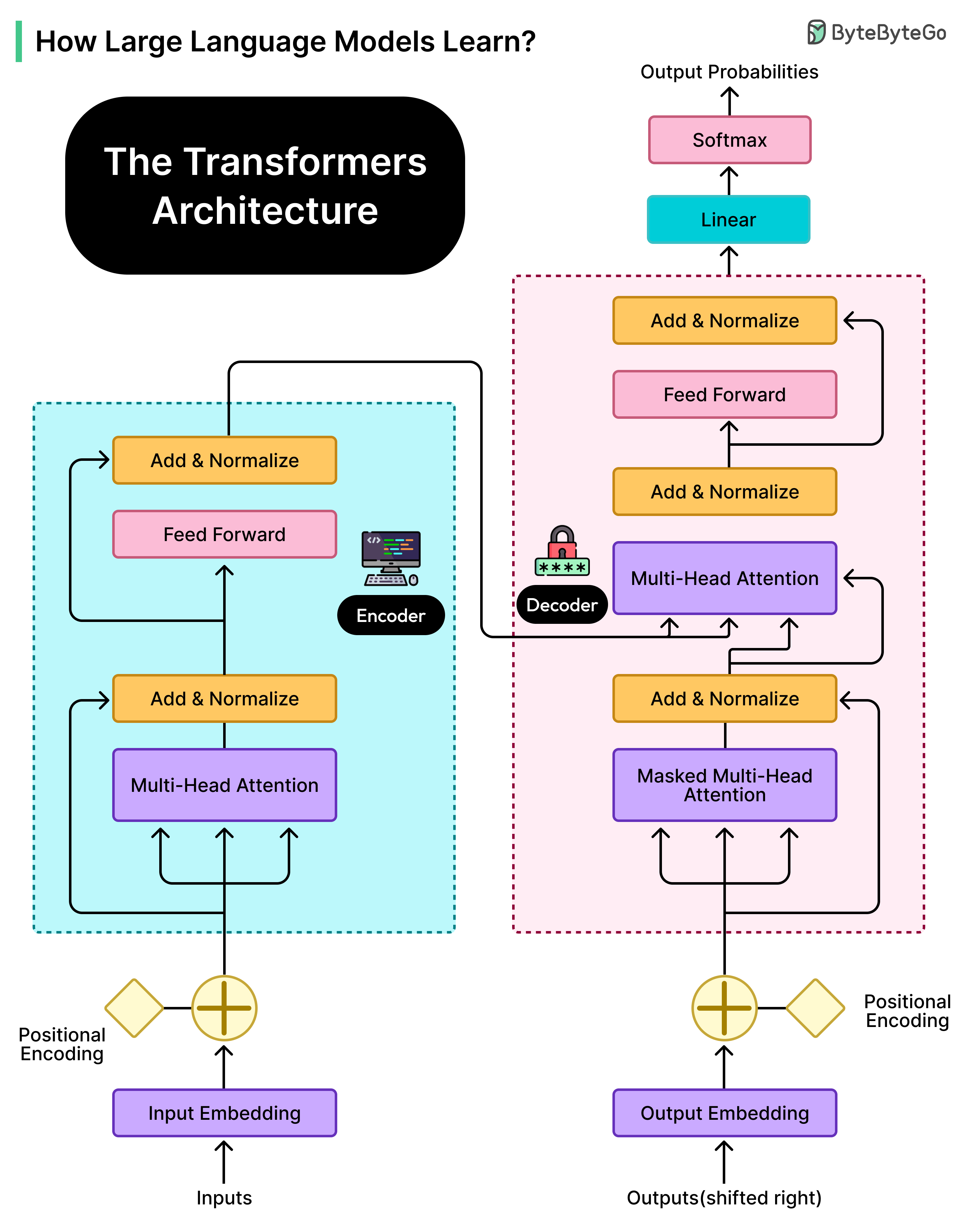
What Models Actually Learn?
LLMs don’t work like search engines or databases, looking up stored facts when asked questions.
Everything an LLM knows is encoded in its parameters, which are billions of numerical values that determine how the model processes and generates text. These parameters are essentially adjustable weights that get tuned during training. When someone asks an LLM about a historical event or a programming concept, the model isn’t retrieving a stored fact. Instead, it’s generating a response based on patterns it learned by processing enormous amounts of text during training.
Think about how humans learn a new language by reading extensively. After reading thousands of books and articles, we
...This excerpt is provided for preview purposes. Full article content is available on the original publication.