From GPT-2 to gpt-oss: Analyzing the Architectural Advances
OpenAI just released their new open-weight LLMs this week: gpt-oss-120b and gpt-oss-20b, their first open-weight models since GPT-2 in 2019. And yes, thanks to some clever optimizations, they can run locally (but more about this later).
This is the first time since GPT-2 that OpenAI has shared a large, fully open-weight model. Earlier GPT models showed how the transformer architecture scales. The 2022 ChatGPT release then made these models mainstream by demonstrating concrete usefulness for writing and knowledge (and later coding) tasks. Now they have shared some long-awaited weight model, and the architecture has some interesting details.
I spent the past few days reading through the code and technical reports to summarize the most interesting details. (Just days after, OpenAI also announced GPT-5, which I will briefly discuss in the context of the gpt-oss models at the end of this article.)
Below is a quick preview of what the article covers. For easier navigation, I recommend using the Table of Contents on the left of on the article page.
Model architecture comparisons with GPT-2
MXFP4 optimization to fit gpt-oss models onto single GPUs
Width versus depth trade-offs (gpt-oss vs Qwen3)
Attention bias and sinks
Benchmarks and comparisons with GPT-5
I hope you find it informative!
1. Model Architecture Overview
Before we discuss the architecture in more detail, let's start with an overview of the two models, gpt-oss-20b and gpt-oss-120b, shown in Figure 1 below.
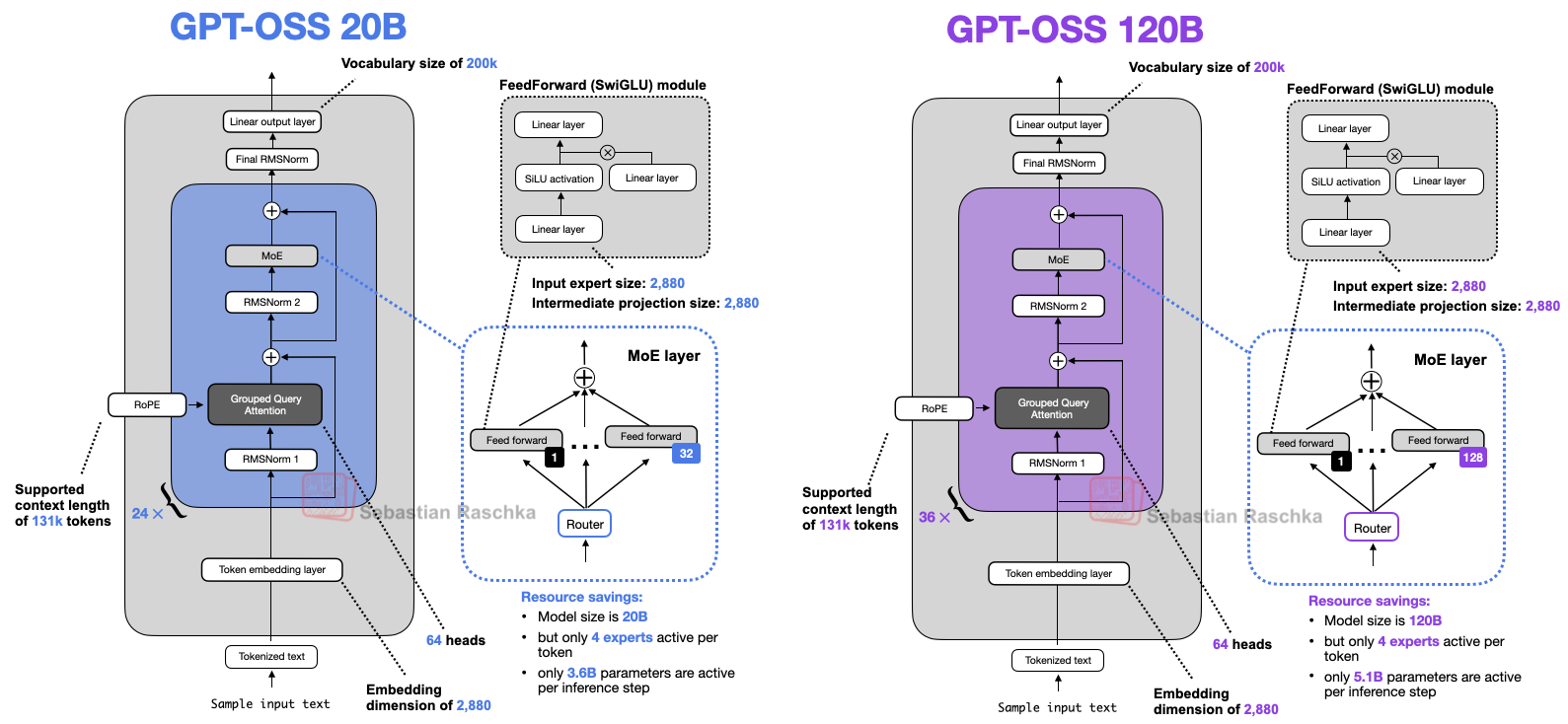
If you have looked at recent LLM architecture diagrams before, or read my previous Big Architecture Comparison article, you may notice that there is nothing novel or unusual at first glance.
This is not surprising, since leading LLM developers tend to use the same base architecture and then apply smaller tweaks. This is pure speculation on my part, but I think this is because
There is significant rotation of employees between these labs.
We still have not found anything better than the transformer architecture. Even though state space models and text diffusion models exist, as far as I know no one has shown that they perform as well as transformers at this scale. (Most of the comparisons I found focus only on benchmark performance. It is still unclear how well the models handle real-world, multi-turn writing and coding tasks. At the time of writing, the highest-ranking non-purely-transformer-based model on the LM Arena is Jamba, which is a
This excerpt is provided for preview purposes. Full article content is available on the original publication.