How Netflix Built a Real-Time Distributed Graph for Internet Scale
2026 AI predictions for builders (Sponsored)

The AI landscape is changing fast—and the way you build AI systems in 2026 will look very different.
Join us live on January 28 as we unpack the first take from Redis’ 2026 predictions report: why AI apps won’t succeed without a unified context engine.
You’ll learn:
One architectural standard for AI across teams
Lower operational overhead via shared context infrastructure
Predictable, production-grade performance
Clear observability and governance for agent data access
Faster time to market for new AI features
Read the full 2026 predictions report →
Netflix is no longer just a streaming service. The company has expanded into live events, mobile gaming, and ad-supported subscription plans. This evolution created an unexpected technical challenge.
To understand the challenge, consider a typical member journey. Assume that a user watches Stranger Things on their smartphone, continues on their smart TV, and then launches the Stranger Things mobile game on a tablet. These activities happen at different times on different devices and involve different platform services. Yet they all belong to the same member experience.
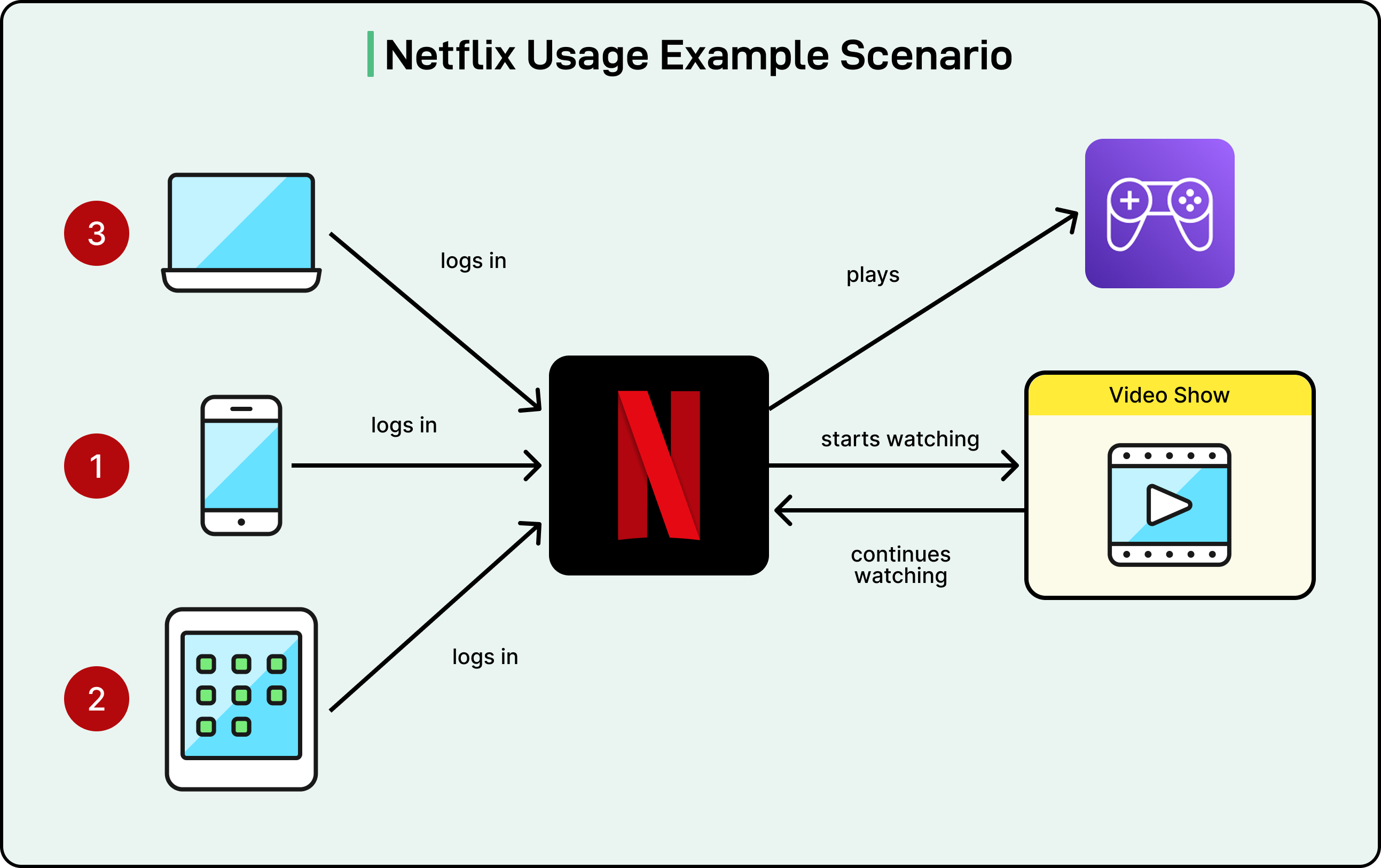
Disclaimer: This post is based on publicly shared details from the Netflix Engineering Team. Please comment if you notice any inaccuracies.
Understanding these cross-domain journeys became critical for creating personalized experiences. However, Netflix’s architecture made this difficult.
Netflix uses a microservices architecture with hundreds of services developed by separate teams. Each service can be developed, deployed, and scaled independently, and teams can choose the best data storage technology for their needs. However, when each service manages its own data, information can become siloed. Video streaming data lives in one database, gaming data in another, and authentication data separately. Traditional data warehouses collect this information, but the data lands in different tables and processes at different times.
Manually stitching together information from dozens of siloed databases became overwhelming. Therefore, the Netflix engineering team needed a different approach to process and store interconnected data while enabling fast queries. They chose a graph representation for the same due to the following reasons:
First, graphs enable fast relationship traversals without expensive database joins.
Second, graphs adapt easily when new connections emerge without significant schema changes.
Third, graphs naturally support pattern detection. Identifying hidden relationships and cycles is more efficient using graph traversals than siloed lookups.
This led Netflix to build the Real-Time Distributed Graph, or RDG. In this article, we will look at the architecture
...This excerpt is provided for preview purposes. Full article content is available on the original publication.