Another Giant Leap: The Rubin CPX Specialized Accelerator & Rack
Nvidia announced the Rubin CPX, a solution that is specifically designed to be optimized for the prefill phase, with the single-die Rubin CPX heavily emphasizing compute FLOPS over memory bandwidth. This is a game changer for inference, and its significance is surpassed only by the March 2024 announcement of the GB200 NVL72 Oberon rack-scale form factor. Only with hardware specialized to the very different phases of inference, prefill and decode, can disaggregated serving achieve its full potential.
As a result, the rack system design gap between Nvidia and its competitors has become canyon-sized. AMD and custom silicon competitors may have made a small step forward in emulating Nvidia’s 72-GPU rack scale design, but Nvidia has just made another Giant Leap, again leaving competitors very distant objects in the rear-view mirror.
AMD and ASIC providers have already been investing heavily to catch up in terms of their own rack-scale solutions. AMD in particular has been working tirelessly to improve their software stack to try to close the gap with Nvidia, but now everyone will needs to redouble their investments yet again as they will have to develop their own prefill chips, delaying further the timeframe with which they can close this gap. With this announcement, all of Nvidia’s competitors will be sent back to the drawing board to reconfigure their entire roadmaps again in a repeat of how Oberon changed roadmaps across the industry.
The Rubin CPX
Because the prefill stage during inference tends to heavily utilize compute (FLOPS) and only lightly use memory bandwidth, running prefill on a chip with lots of expensive HBM featuring very high memory bandwidth is a waste. The answer is a chip that is skinny on memory bandwidth and relatively fat on compute. Enter the Rubin CPX GPU.

The Rubin CPX features 20 PFLOPS of FP4 dense compute but only 2TB/s of memory bandwidth. It also features 128GB of GDDR7 memory, a lower quantity of less expensive memory when compared to the VR200. By comparison, the dual-die R200 chip offers 33.3 PFLOPS of FP4 dense and 288GB of HBM offering 20.5 TB/s of memory bandwidth.
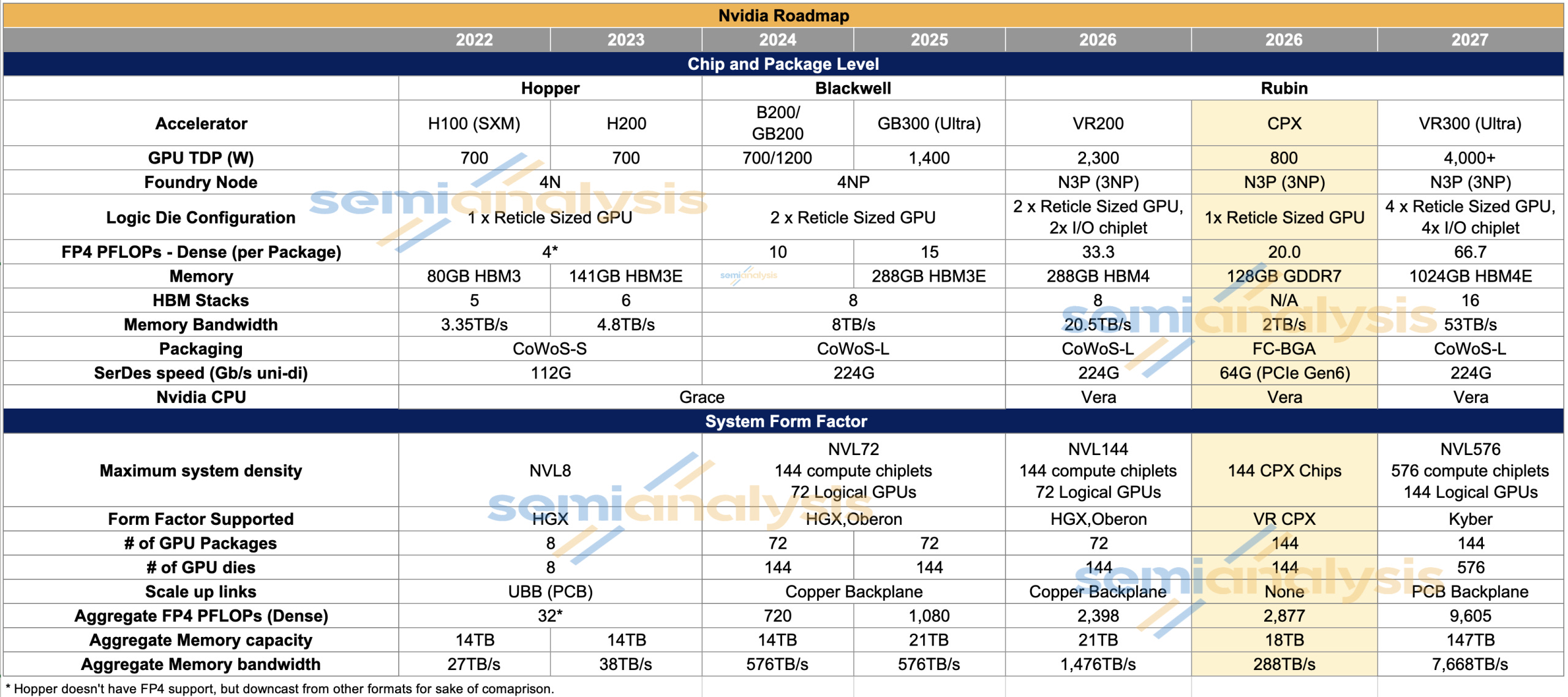
The introduction of the Rubin CPX expands the VR200 family of rack scale servers into three flavors:
VR200 NVL144: 72 GPUs packages across 18 compute trays, with 4 R200 GPU packages in each compute tray.
VR200 NVL144 CPX: 72 Logical GPUs packages in addition to
This excerpt is provided for preview purposes. Full article content is available on the original publication.