How OpenAI, Gemini, and Claude Use Agents to Power Deep Research
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Reinforcement learning from human feedback
13 min read
The article mentions OpenAI's deep research agent uses reinforcement learning to train models for planning multi-step research tasks. RLHF is the specific technique that enables these models to improve decision-making through reward signals, which is fundamental to understanding how these agents learn to coordinate tool calls effectively.
-
Multi-agent system
12 min read
The entire article centers on multi-agent architectures where orchestrator agents coordinate sub-agents for research tasks. Understanding the formal computer science concept of multi-agent systems—including coordination protocols, distributed problem-solving, and agent communication—provides essential theoretical grounding for the practical implementations described.
-
Information retrieval
14 min read
Perplexity's iterative information retrieval loop and the web search agents across all platforms rely on IR principles. This foundational field covers how systems find relevant documents from large collections, relevance ranking, and query refinement—the technical substrate beneath all the deep research capabilities discussed.
Power your company’s IT with AI (Sponsored)

What if you could spend most of your IT resources on innovation, not maintenance?
The latest report from the IBM Institute for Business Value explores how businesses are using intelligent automation to get more out of their technology, drive growth & cost the cost of complexity.
Disclaimer: The details in this post have been derived from the details shared online by OpenAI, Gemini, xAI, Perplexity, Microsoft, Qwen, and Anthropic Engineering Teams. All credit for the technical details goes to OpenAI, Gemini, xAI, Perplexity, Microsoft, Qwen, and Anthropic Engineering Teams. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Deep Research has become a standard capability across modern LLM platforms.
ChatGPT, Gemini, and Claude all support tasks that run for long periods of time and gather information from large portions of the public web.
A typical deep research request may involve dozens of searches, several rounds of filtering, and the careful assembly of a final, well-structured report. For example, a query like “list 100 companies working on AI agents in 2025” does not rely on a single search result. It activates a coordinated system that explores a wide landscape of information over 15 to 30 minutes before presenting a final answer.
This article explains how these systems work behind the scenes.
We will walk through the architecture that enables Deep Research, how different LLMs implement it, how agents coordinate with one another, and how the final report is synthesized and validated before being delivered to the user.
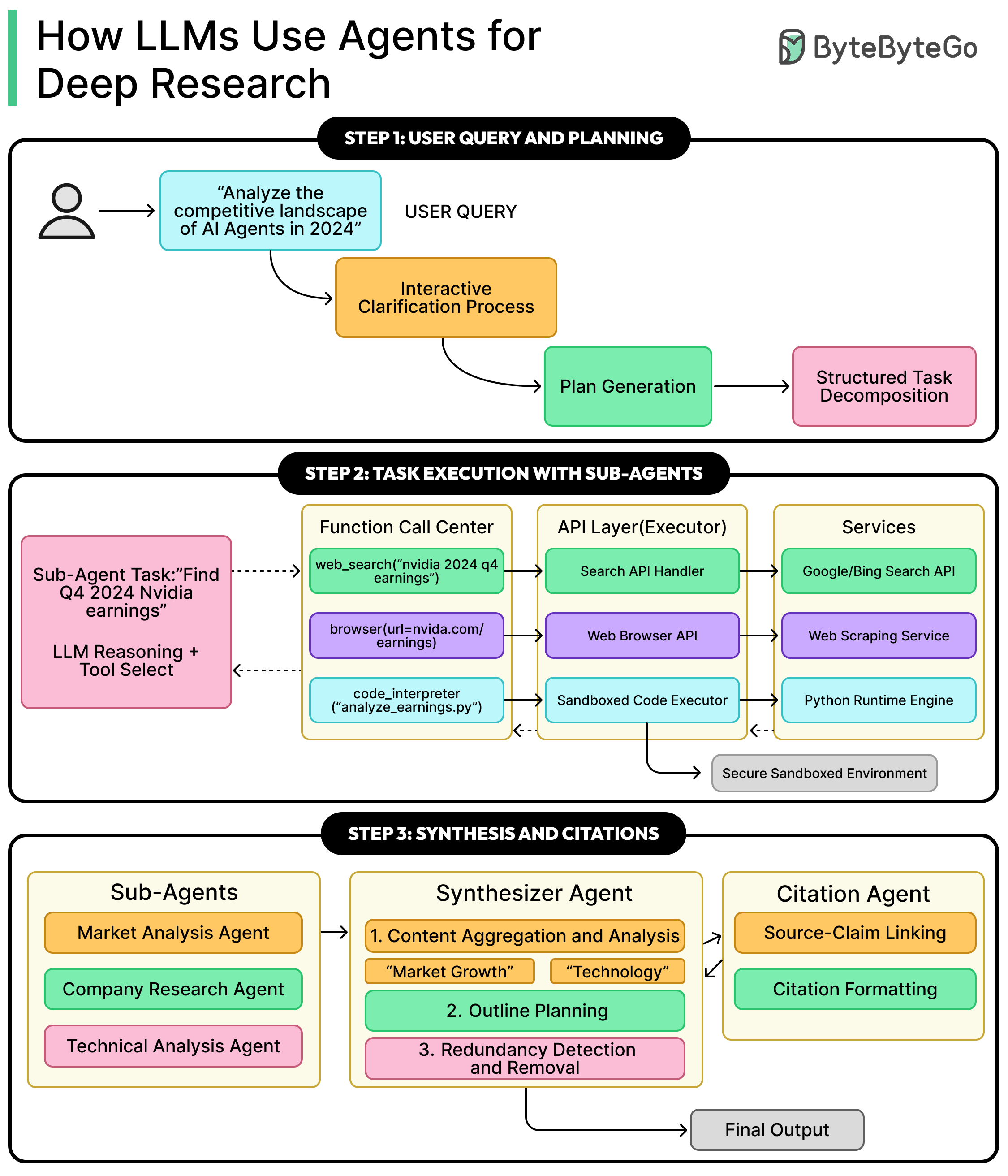
High-Level Architecture
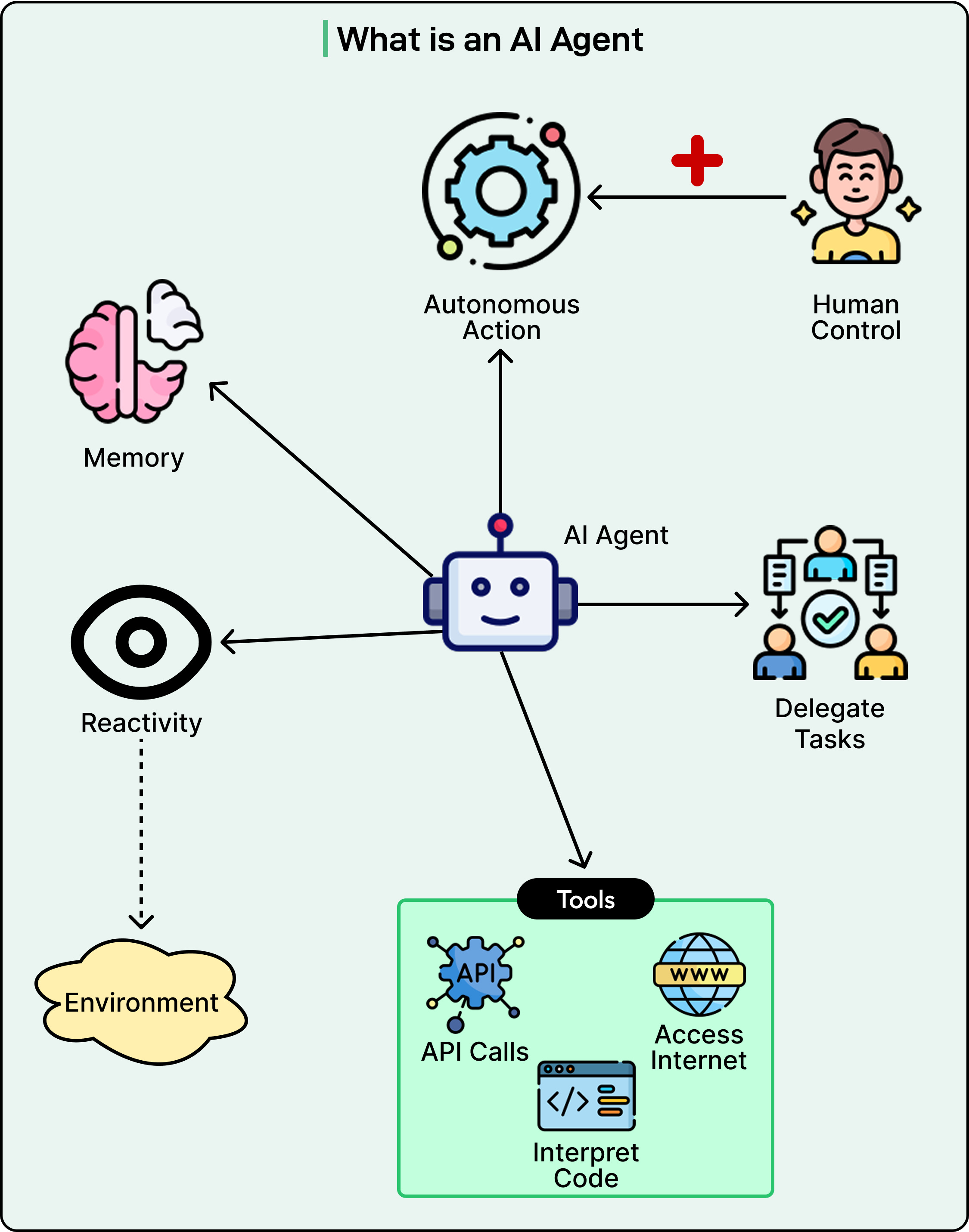
Deep Research systems are built from AI agents that cooperate with each other. In this context, an AI agent is a service driven by an LLM that can accept goals, design workflows to achieve those goals, and interact with its environment through tools such as web search or code execution.
See the diagram below to understand the concept of an AI Agent:
At a high level, the architecture begins with the user request. The user’s query is sent into a multi-agent research system. Inside this system, there is usually an orchestrator or lead agent that takes responsibility for the overall research strategy.
The
...This excerpt is provided for preview purposes. Full article content is available on the original publication.