A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026
If you have struggled a bit to keep up with open-weight model releases this month, this article should catch you up on the main themes.
In this article, I will walk you through the ten main releases in chronological order, with a focus on the architecture similarities and differences:
Arcee AI’s Trinity Large (Jan 27, 2026)
Moonshot AI’s Kimi K2.5 (Jan 27, 2026)
StepFun Step 3.5 Flash (Feb 1, 2026)
Qwen3-Coder-Next (Feb 3, 2026)
z.AI’s GLM-5 (Feb 12, 2026)
MiniMax M2.5 (Feb 12, 2026)
Nanbeige 4.1 3B (Feb 13, 2026)
Qwen 3.5 (Feb 15, 2026)
Ant Group’s Ling 2.5 1T & Ring 2.5 1T (Feb 16, 2026)
Cohere’s Tiny Aya (Feb 17, 2026)
(PS: DeepSeek V4 will be added once released.)
Since there’s a lot of ground to cover, I will be referencing my previous The Big LLM Architecture Comparison article for certain technical topics (like Mixture-of-Experts, QK-Norm, Multi-head Latent Attention, etc.) throughout this article for background information to avoid redundancy in this article.
1. Arcee AI’s Trinity Large: A New US-Based Start-Up Sharing Open-Weight Models
On January 27, Arcee AI (a company I hadn’t had on my radar up to then) began releasing versions of their open-weight 400B Trinity Large LLMs on the model hub, along with two smaller variants:
Their flagship large model is a 400B param Mixture-of-Experts (MoE) with 13B active parameters.
The two smaller variants are Trinity Mini (26B with 3B active parameters) and Trinity Nano (6B with 1B active parameters).
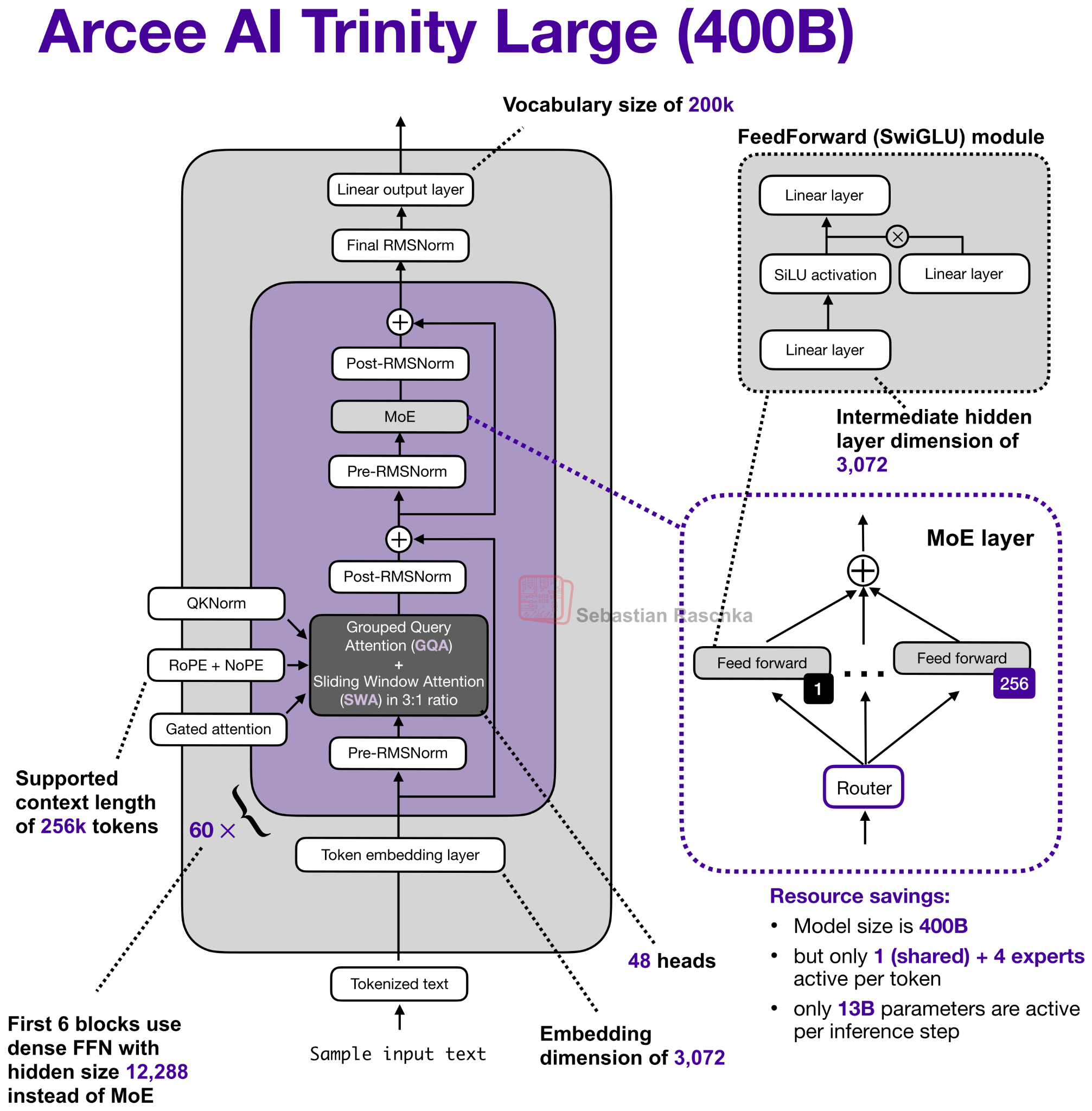
Along with the model weights, Arcee AI also released a nice technical report on GitHub (as of Feb 18 also on arxiv) with lots of details.
So, let’s take a closer look at the 400B flagship model. Figure 2 below compares it to z.AI’s GLM-4.5, which is perhaps the most similar model due to its size with 355B parameters.
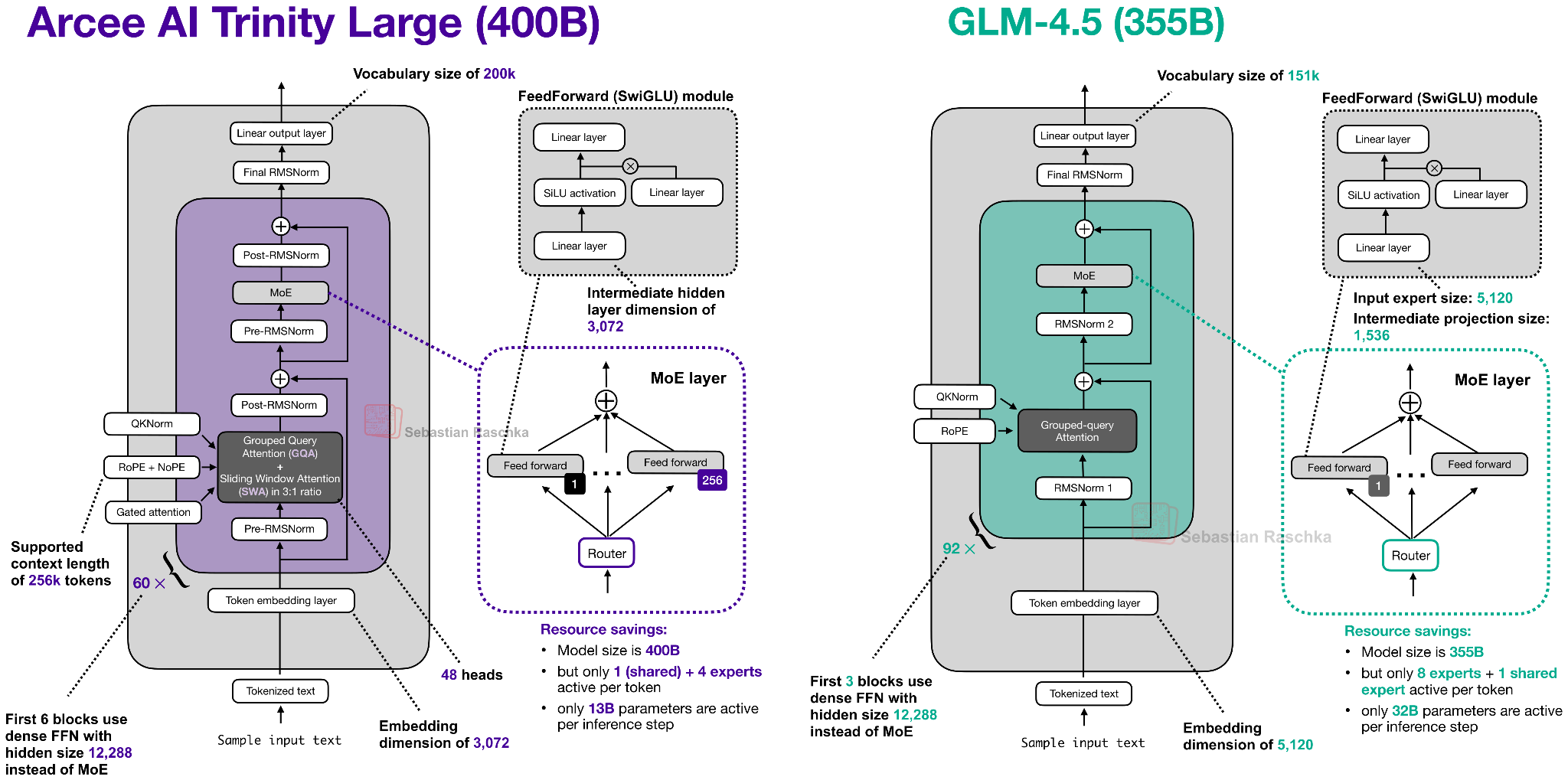
As we can see in the Trinity and GLM-4.5 comparison, there are several interesting architectural components added to the Trinity model.
First, there are the alternating local:global (sliding window) attention layers (SWA) like in Gemma 3, Olmo 3, Xiaomi MiMo, etc. In short, SWA is a type of sparse (local) attention pattern where each token attends only to a fixed-size
...This excerpt is provided for preview purposes. Full article content is available on the original publication.