The State Of LLMs 2025: Progress, Problems, and Predictions
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Reinforcement learning from human feedback
13 min read
The article extensively discusses RLHF as a foundational technique that brought us ChatGPT, and contrasts it with newer RLVR approaches. Understanding RLHF's mechanics and history provides essential context for why RLVR represents a significant shift.
-
Mixture of experts
12 min read
DeepSeek V3, which the article highlights as a pivotal cost-efficiency breakthrough, uses a Mixture of Experts (MoE) architecture with 671B parameters. Understanding MoE explains how DeepSeek achieved state-of-the-art performance at dramatically lower training costs.
-
Proximal policy optimization
11 min read
The article identifies PPO as the algorithm behind the original ChatGPT's RLHF training and contrasts it with GRPO. Understanding PPO's mechanics illuminates why GRPO represents an algorithmic evolution in how reasoning models are trained.
As 2025 comes to a close, I want to look back at some of the year’s most important developments in large language models, reflect on the limitations and open problems that remain, and share a few thoughts on what might come next.
As I tend to say every year, 2025 was a very eventful year for LLMs and AI, and this year, there was no sign of progress saturating or slowing down.
1. The Year of Reasoning, RLVR, and GRPO
There are many interesting topics I want to cover, but let’s start chronologically in January 2025.
Scaling still worked, but it didn’t really change how LLMs behaved or felt in practice (the only exception to that was OpenAI’s freshly released o1, which added reasoning traces). So, when DeepSeek released their R1 paper in January 2025, which showed that reasoning-like behavior can be developed with reinforcement learning, it was a really big deal. (Reasoning, in the context of LLMs, means that the model explains its answer, and this explanation itself often leads to improved answer accuracy.)
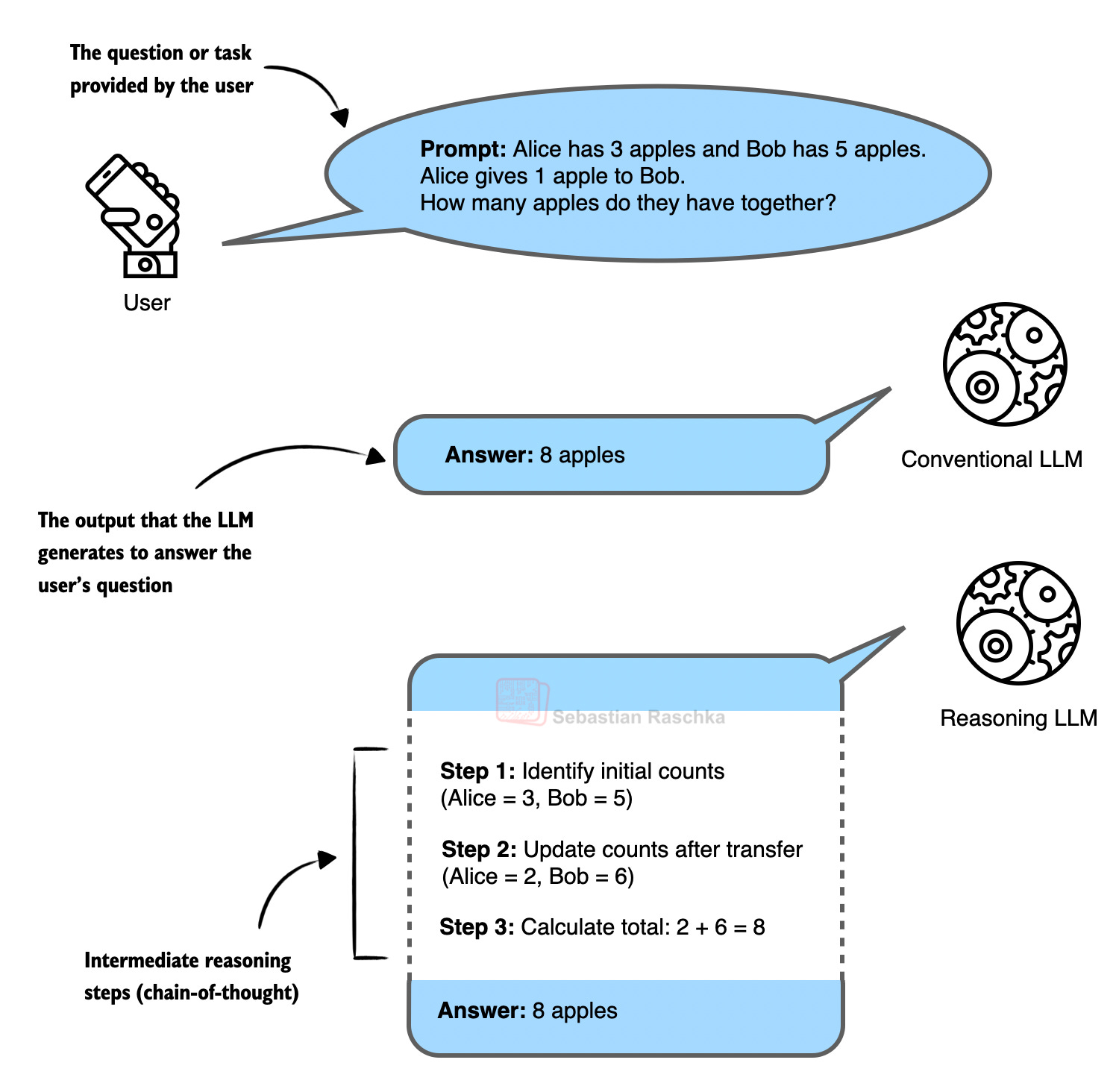
1.1 The DeepSeek Moment
DeepSeek R1 got a lot of attention for various reasons:
First, DeepSeek R1 was released as an open-weight model that performed really well and was comparable to the best proprietary models (ChatGPT, Gemini, etc.) at the time.
Second, the DeepSeek R1 paper prompted many people, especially investors and journalists, to revisit the earlier DeepSeek V3 paper from December 2024. This then led to a revised conclusion that while training state-of-the-art models is still expensive, it may be an order of magnitude cheaper than previously assumed, with estimates closer to 5 million dollars rather than 50 or 500 million.
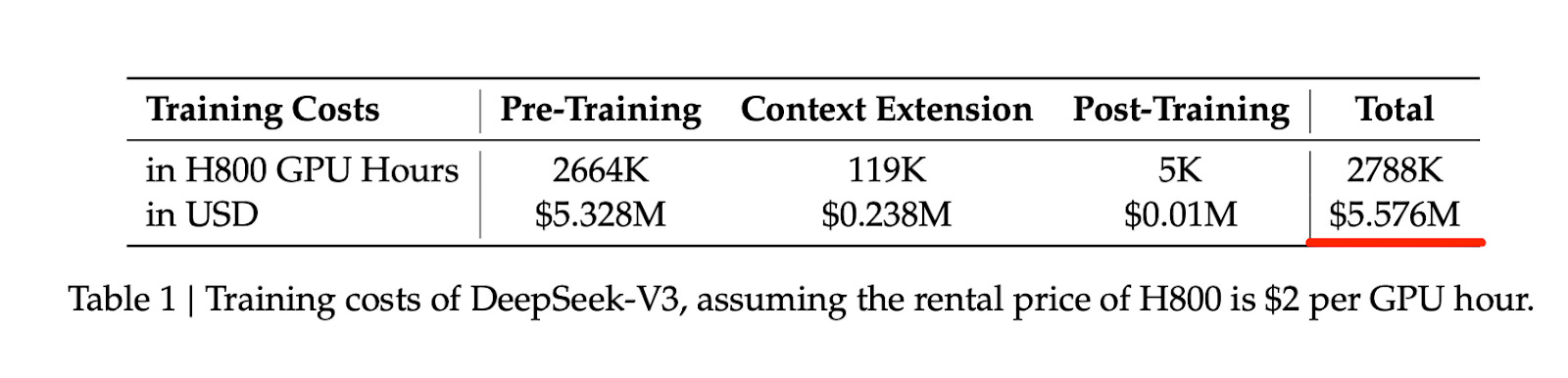
The DeepSeek R1 supplementary materials estimate that training the DeepSeek R1 model on top of DeepSeek V3 costs another $294,000, which is again much lower than everyone believed.
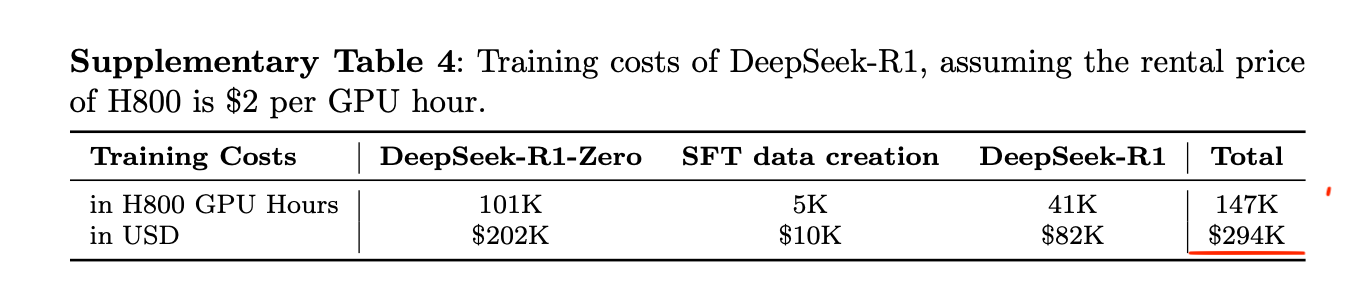
Of course, there are many caveats to the 5-million-dollar estimate. For instance, it captures only the compute credit cost for the final model run, but it doesn’t factor in the researchers’ salaries and other
...This excerpt is provided for preview purposes. Full article content is available on the original publication.