How Large Language Models Learn
Overcome the challenges of deploying LLMs securely and at scale (Sponsored)

To scale with LLMs, you need to know how to monitor them effectively. In this eBook, get practical strategies to monitor, debug, and secure LLM-powered applications. From tracing multi-step workflows and detecting prompt injection attacks to evaluating response quality and tracking token usage, you’ll learn best practices for integrating observability into every layer of your LLM stack.
When we talk about large language models “learning,” we can end up creating a misleading impression. The word “learning” suggests something similar to human learning, complete with understanding, reasoning, and insight.
However, that’s not what happens inside these systems. LLMs don’t learn the way you learned to code or solve problems. Instead, they follow repetitive mathematical procedures billions of times, adjusting countless internal parameters until they become very good at mimicking patterns in text.
This distinction matters more than you might think because it changes the way LLMs generate their answers.
Understanding how LLMs actually work helps you know when to trust their outputs and when to be skeptical. It reveals why they can write convincing essays about topics they don’t fully understand, and why they sometimes fail in surprising ways.
In this article, we’ll explore three core concepts that have a key impact on the working of LLMs: loss functions (how we measure failure), gradient descent (how we make improvements), and next-token prediction (what LLMs actually do).
The Foundation: Loss Functions
Before an LLM can learn anything, we need a way to measure how badly it’s performing. This measurement is called a loss function.
Think of it as a scoring system that provides a single number representing how wrong the model is. The higher the number, the worse the performance. The goal of training is to make this number as small as possible.
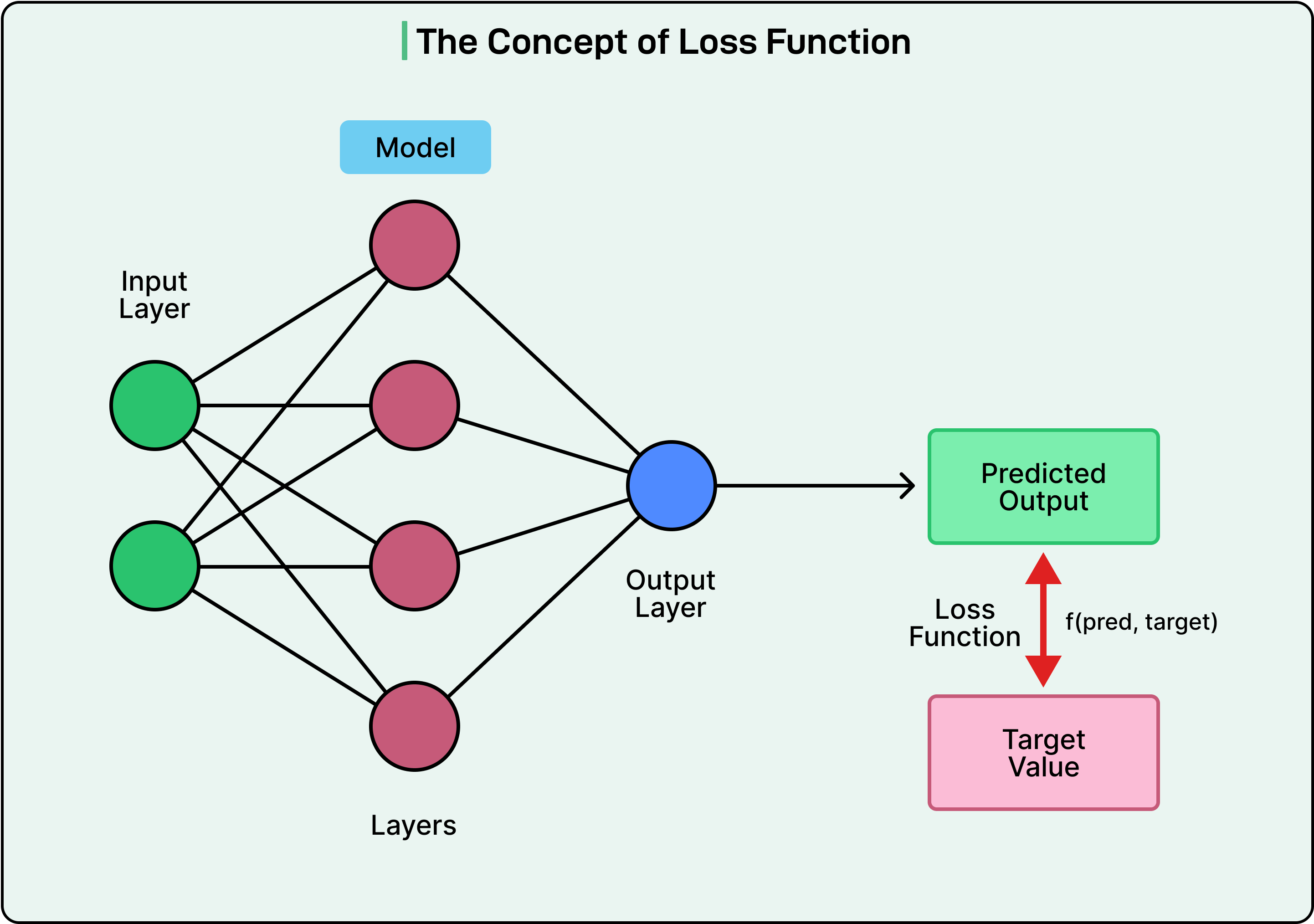
However, you can’t just pick any measurement and expect it to work. A good loss function must satisfy three critical requirements:
First, it must be specific. It needs to measure something concrete and not vague. If someone told you to “build an intelligent computer,” you’d struggle because intelligence itself is hard to define. Would a system that passes an IQ test count? Probably not, since computers have passed IQ tests for over a decade without being useful for much else. For LLMs, we pick something very specific, such as predicting the next word in a sequence correctly. This
This excerpt is provided for preview purposes. Full article content is available on the original publication.