RL Environments and RL for Science: Data Foundries and Multi-Agent Architectures
We’re hiring for AI Analysts and Tokenomics Analyst roles. Apply here or reach out directly.
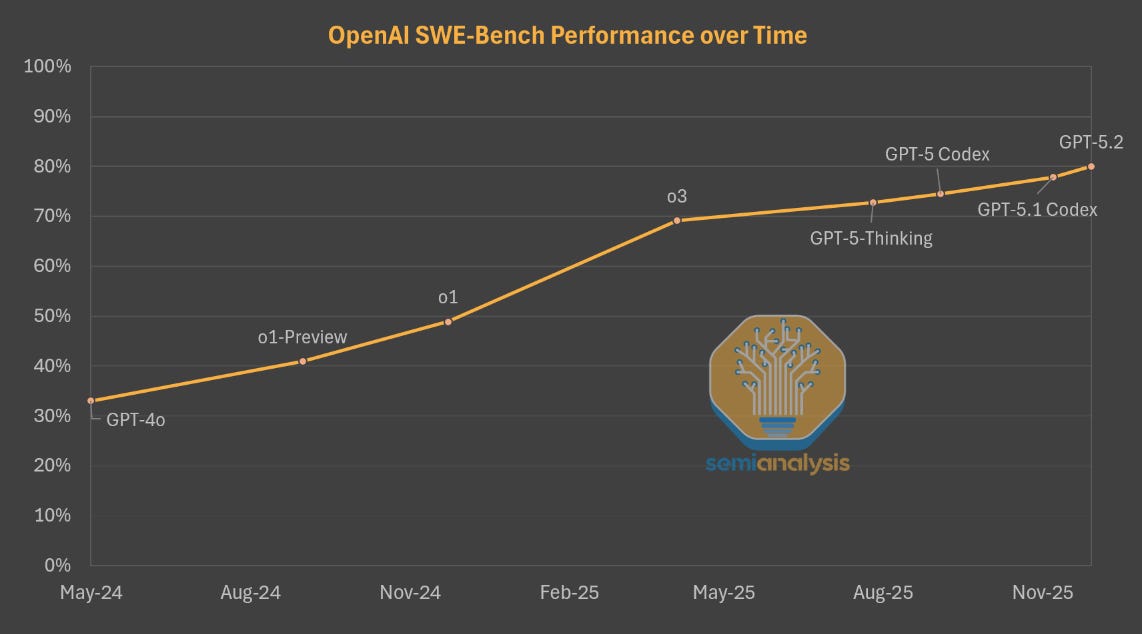
Last June, we argued that scaling RL is the critical path to unlocking further AI capabilities. As we will show, the past several months have affirmed our thesis: major capability gains are coming from ramping RL compute. Pre-training continues to see further optimizations, but the lab’s are laser focused on scaling compute for RL.
The best example of this is demonstrated by OpenAI. The company has used the same base model, GPT-4o, for all their recent flagship models: o1, o3, and GPT-5 series. Gains in the performance of OpenAI’s models for 18 months were being driven by post-training and scaling up RL compute alone. OpenAI has now fixed their pretraining problems, so with that vector of scaling unlocked, progress will be even more rapid.
This is not to say that pre-training is dead: Anthropic, xAI, and especially Google all derived significant gains from scaling up pre-training. But OpenAI’s progress last year and ability to keep up using an older base model was existence proof of the efficacy of post-training.
Scaling up RL is difficult as it requires a steady stream of tasks the model needs to solve and learn from. Pre-training had the entire internet to train on, but equivalent corpus for RL is yet to be fully created. Most RL data and tasks must be constructed from scratch, which can be quite labor intensive.
Making the models “do the homework” started with math problems, which are easy to grade. Methods have since advanced, including branching out to newer domains like healthcare and financial modelling. To do this, models are placed in increasingly specialized “environments” that require the model to do these tasks.
Aggregating tasks and data can be done manually, or through the curation of high signal user data. The latter is what gives companies like Windsurf and Cursor the ability to post-train their own competitive models despite not having the resources of a lab.
These post-training efforts have improved model capability in domains like coding, but also model utility: models are more usable in everyday tools like Excel and PowerPoint.
To measure how much models are improving in utility and capability, OpenAI created an eval called GDPval. This eval covers 1000+ tasks across 44 occupations, picked from sectors that representing >5% of the economy. Many of these tasks are digital but require
...This excerpt is provided for preview purposes. Full article content is available on the original publication.