How OpenAI Scaled to 800 Million Users With Postgres
Sentry’s AI debugger fixes code wherever it breaks (Sponsored)

🤖Most AI coding tools only see your source code. Seer, Sentry’s AI debugging agent, uses everything Sentry knows about how your code has behaved in production to debug locally, in your PR, and in production.
🛠️How it works:
Seer scans & analyzes issues using all Sentry’s available context.
In development, Seer debugs alongside you as you build
In review, Seer alerts you to bugs that are likely to break production, not nits
In production, Seer can find a bug’s root cause, suggest a fix, open a PR automatically, or send the fix to your preferred IDE.
OpenAI scaled PostgreSQL to handle millions of queries per second for 800 million ChatGPT users. They did it with just a single primary writer supported by read replicas.
At first glance, this should sound impossible. The common wisdom suggests that beyond a certain scale, you must shard the database or risk failure. The conventional playbook recommends embracing the complexity of splitting the data across multiple independent databases.
OpenAI’s engineering team chose a different path. They decided to see just how far they could push PostgreSQL.
Over the past year, their database load grew by more than 10X. They experienced the familiar pattern of database-related incidents: cache layer failures causing sudden read spikes, expensive queries consuming CPU, and write storms from new features. Yet through systematic optimization across every layer of their stack, they achieved five-nines availability with low double-digit millisecond latency. But the road wasn’t easy.
In this article, we will look at the challenges OpenAI faced while scaling Postgres and how the team handled the various scenarios.
Disclaimer: This post is based on publicly shared details from the OpenAI Engineering Team. Please comment if you notice any inaccuracies.
Understanding Single-Primary Architecture
A single-primary architecture means one database instance handles all writes, while multiple read replicas handle read queries.
See the diagram below:
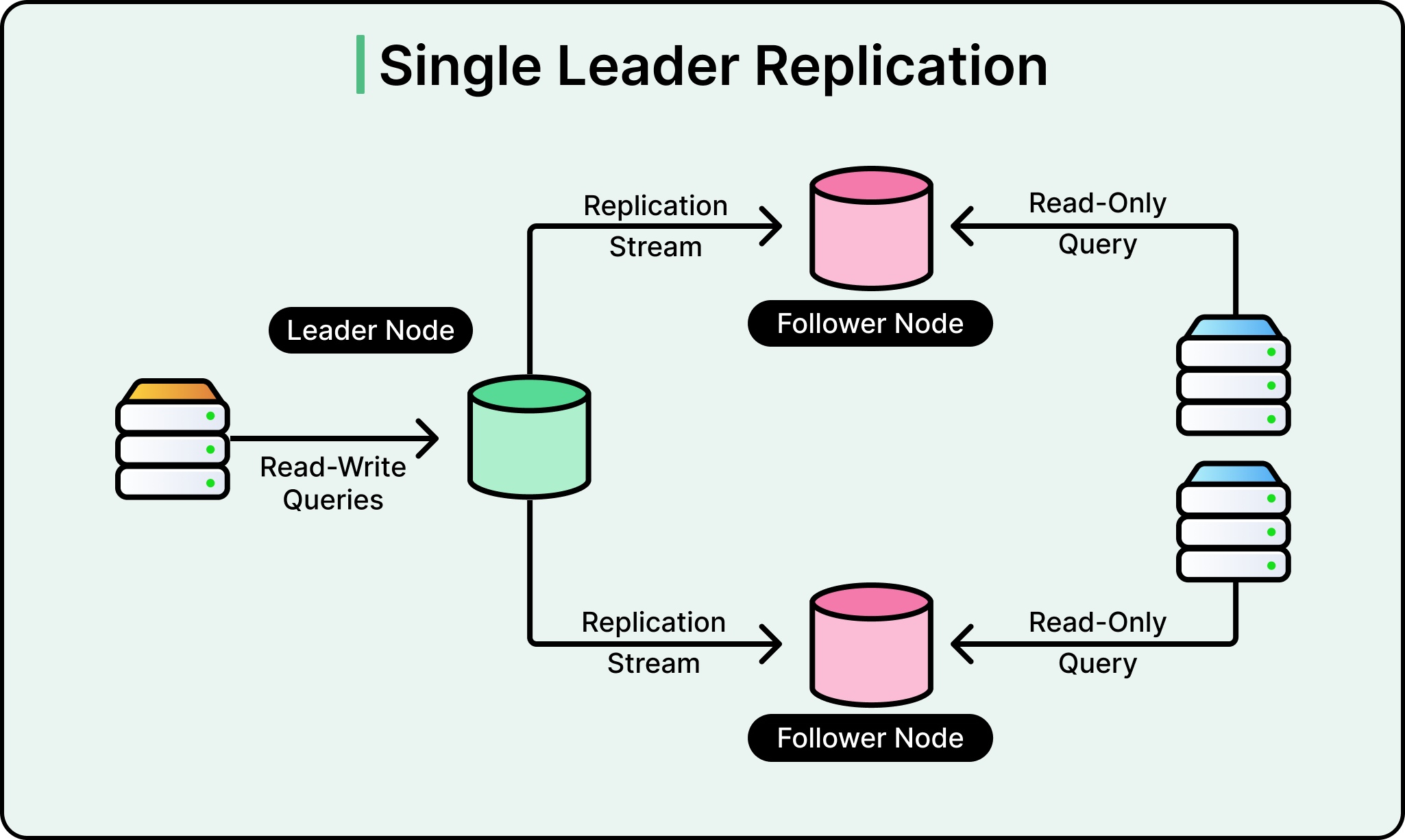
This design creates an inherent bottleneck because writes cannot be distributed. However, for read-heavy workloads like ChatGPT, where users primarily fetch data rather than modify it, this architecture can scale effectively if properly optimized.
OpenAI avoided sharding its PostgreSQL deployment for pragmatic reasons. Sharding would require modifying hundreds of application endpoints and could take months or years to complete. Since their workload is primarily read-heavy and current optimizations provide sufficient capacity, sharding remains a future consideration rather than an immediate necessity.
So
...This excerpt is provided for preview purposes. Full article content is available on the original publication.