LLMs as Ground Truth
In this post I will show:
How to save around 90% of LLM cost of your customer service agent in production.
How to combine LLMs with old-school ML to acquire an accurate and cost-efficient hybrid system.
In our previous article, we described the "overfitting" of LLMs via prompting: https://nobsai.substack.com/p/the-necessity-of-overfitting-llm By crafting a very precise, elaborate prompt, she was able to carefully detect the true intent of a customer question and assign it to a correct class.
However, detailed prompts like this have their problems:
They are brittle - as demonstrated in the article, classification results can often be unstable, influenced by parameters like temperature.
They are costly - their length and level of detail mean they contain a significant number of tokens, which increases expense.
In this article, I demonstrate a solution to the second problem. In the course of our real-life work, we replaced the expensive LLM with a significantly more affordable model. By leveraging the "overfitted" prompts as a source of high-quality training data, we successfully trained a traditional machine learning classifier that performs effectively in production. This approach enables the system to operate at minimal cost.
The concept is illustrated in the image below:
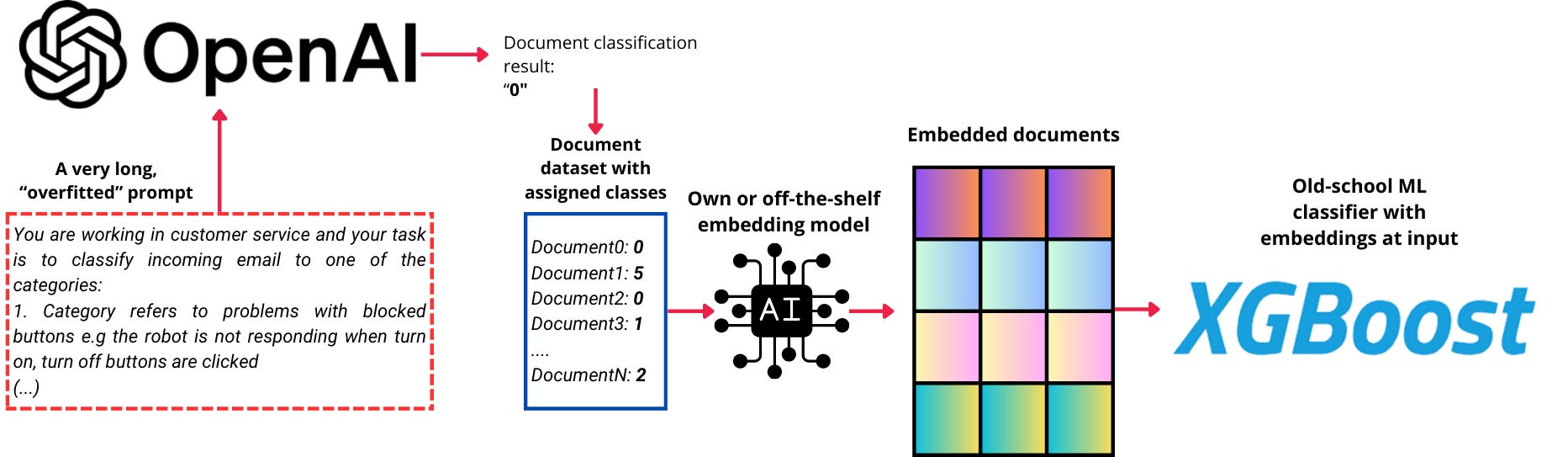
Before the era of LLMs, a significant amount of time (and money) was usually spent on annotating data. Today, a well-designed prompt can transform an LLM into an excellent annotator for our purposes. While it may incur some cost—since the prompts need to be sufficiently detailed and extensive to ensure high-quality "classification"—this investment is a one-time effort aimed at generating training data.
The pipeline:
Refine your prompt to ensure it is detailed enough to capture the necessary nuances. Incorporate the secrets of the business, so that it correctly identifies the intents in text (as done in https://nobsai.substack.com/p/the-necessity-of-overfitting-llm)
Once the prompt is finalized and delivers satisfactory classification quality, use it to process your data and generate the "ground truth." In my case, I required results for approximately 2,000 examples per class.
Embed the data - I used ada-002 embedder from OpenAI, without any finetuning, and it proved good enough for this case. Much better results will likely come from finetuning the embedder - even if it's a smallish model from Huggingface.
Feed the embeddings, together with their class labels assigned by an LLM, to a classifier like XGBoost.
The result?
I have trained the classifiers for 3 classes. Each class reflects a
...This excerpt is provided for preview purposes. Full article content is available on the original publication.