InferenceMAX™: Open Source Inference Benchmarking
LLM Inference performance is driven by two pillars, hardware and software. While hardware innovation drives step jumps in performance every year through the release of new GPUs/XPUs and new systems, software evolves every single day, delivering continuous performance gains on top of these step jumps.
AI software like SGLang, vLLM, TensorRT-LLM, CUDA, and ROCm achieve continuous improvement in performance through kernel-level optimizations, distributed inference strategies, and scheduling innovations that increase the Pareto frontier of performance in incremental releases that can be just days apart.
This pace of software advancement creates a challenge: benchmarks conducted at a fixed point in time quickly go stale and do not represent the performance that can be achieved with the latest software packages.
InferenceMAX™, an open-source automated benchmark designed to move at the same rapid speed as the software ecosystem itself, is built to address this challenge.
InferenceMAX™ runs our suite of benchmarks every night on hundreds of chips, continually re-benchmarking the world’s most popular open-source inference frameworks and models to track real performance in real-time. As these software stacks improve, InferenceMAX™ captures that progress in near real-time, providing a live indicator of inference performance progress. A live dashboard is available for free publicly at https://inferencemax.ai/.
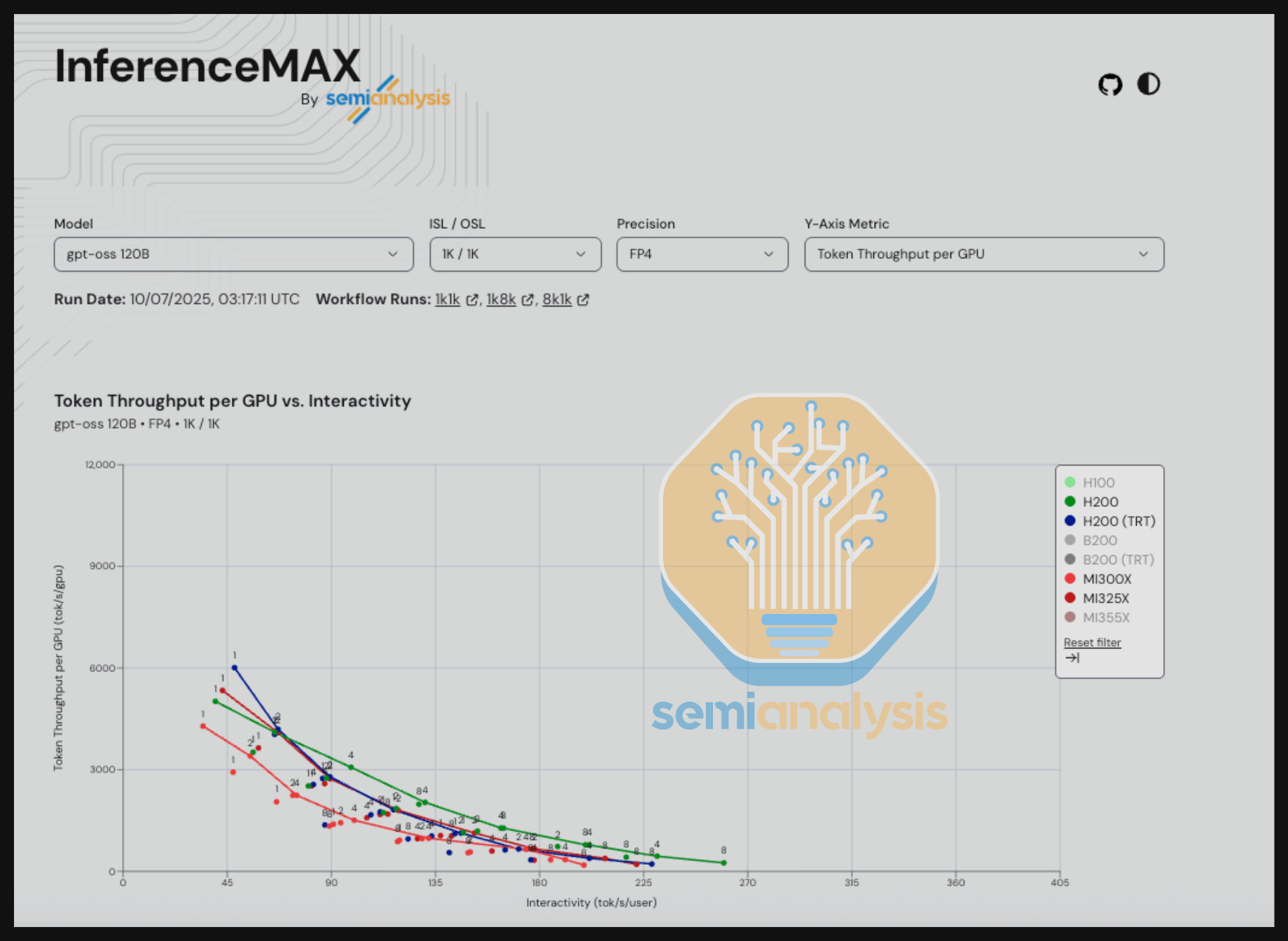
AMD and Nvidia GPUs can both deliver competitive performance for different sets of workloads, with AMD performing best for some types of workloads and Nvidia excelling at others. Indeed, both ecosystems are advancing rapidly!
There are many nuances and considerations when analyzing the results from InferenceMAX™, and this is in no small part because it is designed to be a neutral benchmark, not cherry-picked to promote any specific vendor or solution. As such, there are models and interactivity (tok/s/user) levels where AMD currently does better against Nvidia GPUs of the same generation, and there are also interactivity levels where Nvidia currently does better. The goal of InferenceMAX™ is simple but ambitious — to provide benchmarks that both emulate real world applications as much as possible and reflect the continuous pace of software innovation.
For the initial InferenceMAX™ v1 release, we are benchmarking the GB200 NVL72, B200, MI355X, H200, MI325X, H100 and MI300X. Over the next two months, we’re expanding InferenceMAX™ to include Google TPU and AWS Trainium backends, making it the first truly multi-vendor open benchmark across AMD, NVIDIA, and custom accelerators.
InferenceMAX™ v1 is far from perfect, but we believe
...This excerpt is provided for preview purposes. Full article content is available on the original publication.