Building A GPT-Style LLM Classifier From Scratch
In this article, I want to show you how to transform pretrained large language models (LLMs) into strong text classifiers.
But why focus on classification? First, finetuning a pretrained model for classification offers a gentle yet effective introduction to model finetuning. Second, many real-world and business challenges revolve around text classification: spam detection, sentiment analysis, customer feedback categorization, topic labeling, and more.
What You’ll Learn in This Article
To celebrate the book’s release, I’m sharing an excerpt from one of the chapters that walks you through how to finetune a pretrained LLM as a spam classifier.
Important Note
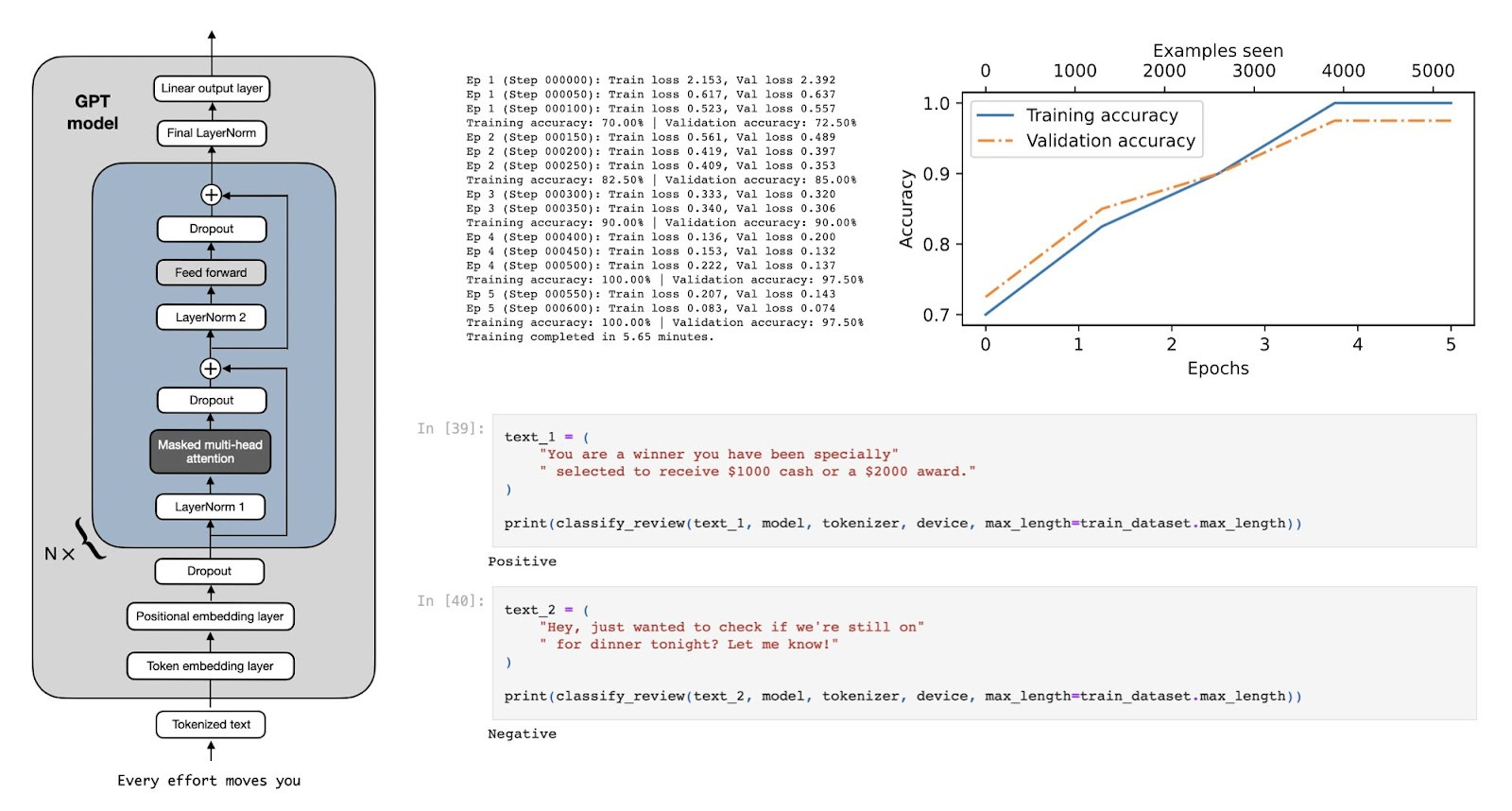
The chapter on classification finetuning is 35 pages long—too long for a single article. So, in this post, I’ll focus on a ~10-page subset that introduces the context and core concepts behind classification finetuning.
Additionally, I’ll share insights from some extra experiments that aren’t included in the book and address common questions readers might have. (Please note that the excerpt below is based on my personal draft before Manning’s professional text editing and final figure design.)
The full code for this excerpt can be found here on GitHub.
In addition, I'll also answer 7 questions you might have regarding training LLM classifiers:
1) Do we need to train all layers?
2) Why finetuning the last token, not the first token?
3) How does BERT compare to GPT performance-wise?
4) Should we disable the causal mask?
5) What impact does increasing the model size have?
6) What improvements can we expect from LoRA?
7) Padding or no padding?
Happy reading!
Different categories of finetuning
The most common ways to finetune language models are instruction finetuning and classification finetuning. Instruction finetuning involves training a language model on a set of tasks using specific instructions to improve its ability to understand and execute tasks described in natural language prompts, as illustrated in Figure 1 below.

The next chapter will discuss instruction finetuning, as illustrated in Figure 1 above. Meanwhile, this chapter is centered on classification finetuning, a concept you might already be acquainted with if you have a background in machine learning.
In
...This excerpt is provided for preview purposes. Full article content is available on the original publication.