Vera Rubin – Extreme Co-Design: An Evolution from Grace Blackwell Oberon

At CES 2026, Nvidia officially announced in detail all 6 Rubin platform products: the Rubin GPU, Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, and Spectrum-6. VR NVL72 is the second generation of Nvidia’s rack scale Oberon architecture that takes the stage. With competition catching up on rack scale game, Trainium 3 in the Gen2 UltraServer, AMD MI450X Helios Racks, and Google’s TPU which was at rack scale even before GB200, Nvidia answers with “extreme co-design” supremacy. With extreme co-design, Nvidia takes rack scale integration to the next level. Rack system becomes a unit of compute, a single distributed accelerator, and Nvidia designs the system.
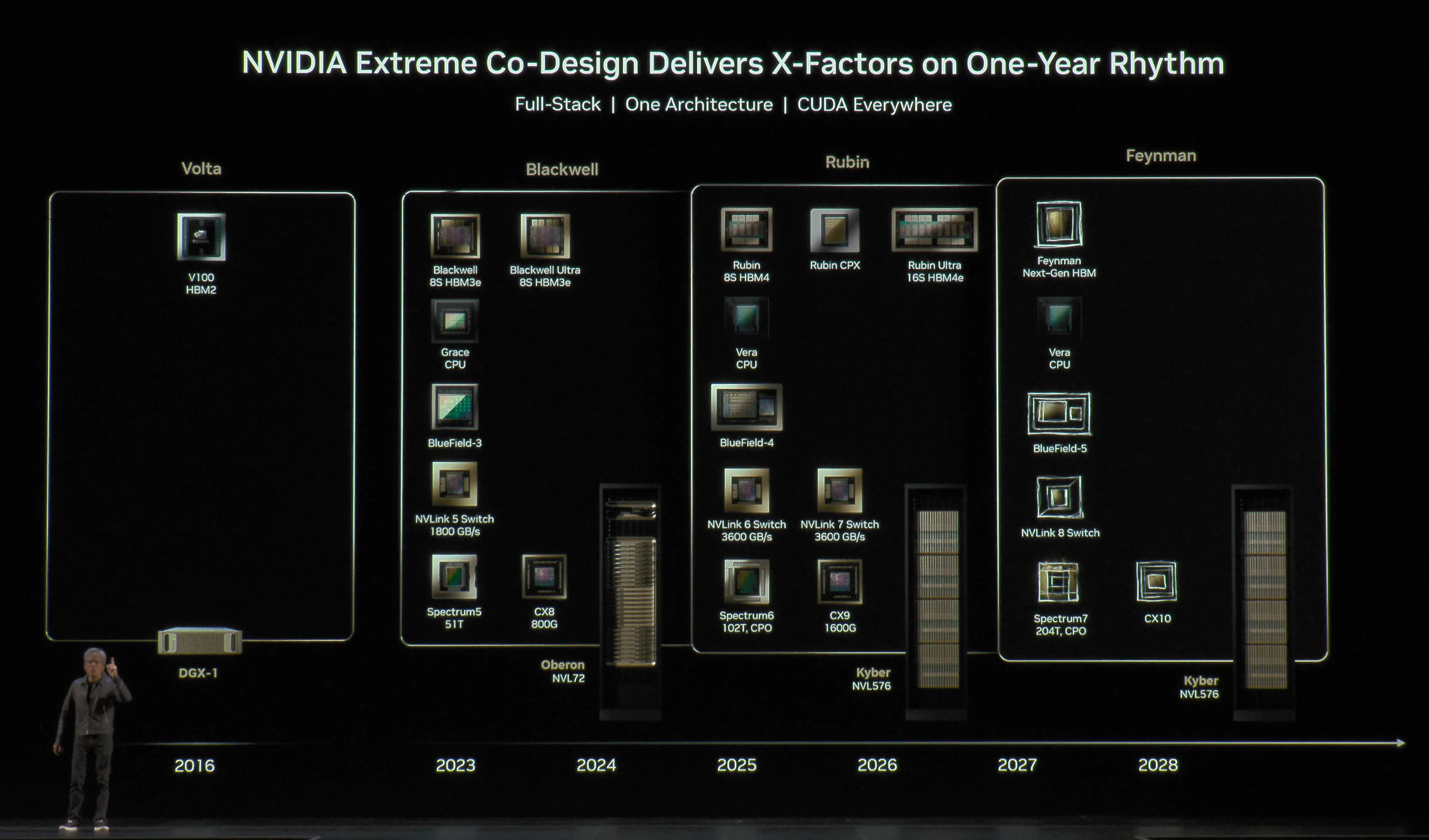
For the Vera Rubin platform, Nvidia is asserting even more control over the system and rack level design. Rack scale integration and assembly have become more challenging, as every component is being pushed to the limit, whilst also optimizing for cost efficiency. VR NVL72 has a much more holistic design with a modular approach compared to Grace Blackwell for the purpose of integration efficiency and throughput.
Nvidia’s competitiveness strengthens with its extreme co-design supremacy. It is the only player with the best in class or close to the best in class silicon product offerings for all the major silicon contents in an Nvidia trail-blazed AI server system design. Nvidia offers the best accelerator, a SOTA scale up switch, the best NIC, and one of the best Ethernet networking switch, and a much improved purpose-designed CPU. No other competitors have such a complete suite of integrated silicon products.
In the sections below, we will discuss the 6 silicon products of the Vera Rubin platform at the silicon level. Then, we will discuss the rack and compute tray evolution from Grace Blackwell to Vera Rubin from the design perspective and the implication to components: cables, connectors, PCB, thermal, mechanical, and power.
Next, we will discuss the major networks of the VR NVL72 system, namely the scale up NVLink 6 network and the backend scale out network. We will discuss the logistical implications of much more limited hyperscaler customisation and the assembly supplier landscape.
Lastly, the report ends with a discussion on the TCO of the VR NVL72 system as well as the BoM and Power Budget estimate supporting the TCO analysis. Behind the paywall, we also provide readers with insight into Nvidia’s plans for their Groq IP. We will also cover some of the
...This excerpt is provided for preview purposes. Full article content is available on the original publication.