SerDes Matters!
We recently discussed that it makes sense to right-size an AI cluster to fit a particular family of workloads. Specifically, the user requirements of workloads can result in similarly shaped infrastructure requirements:
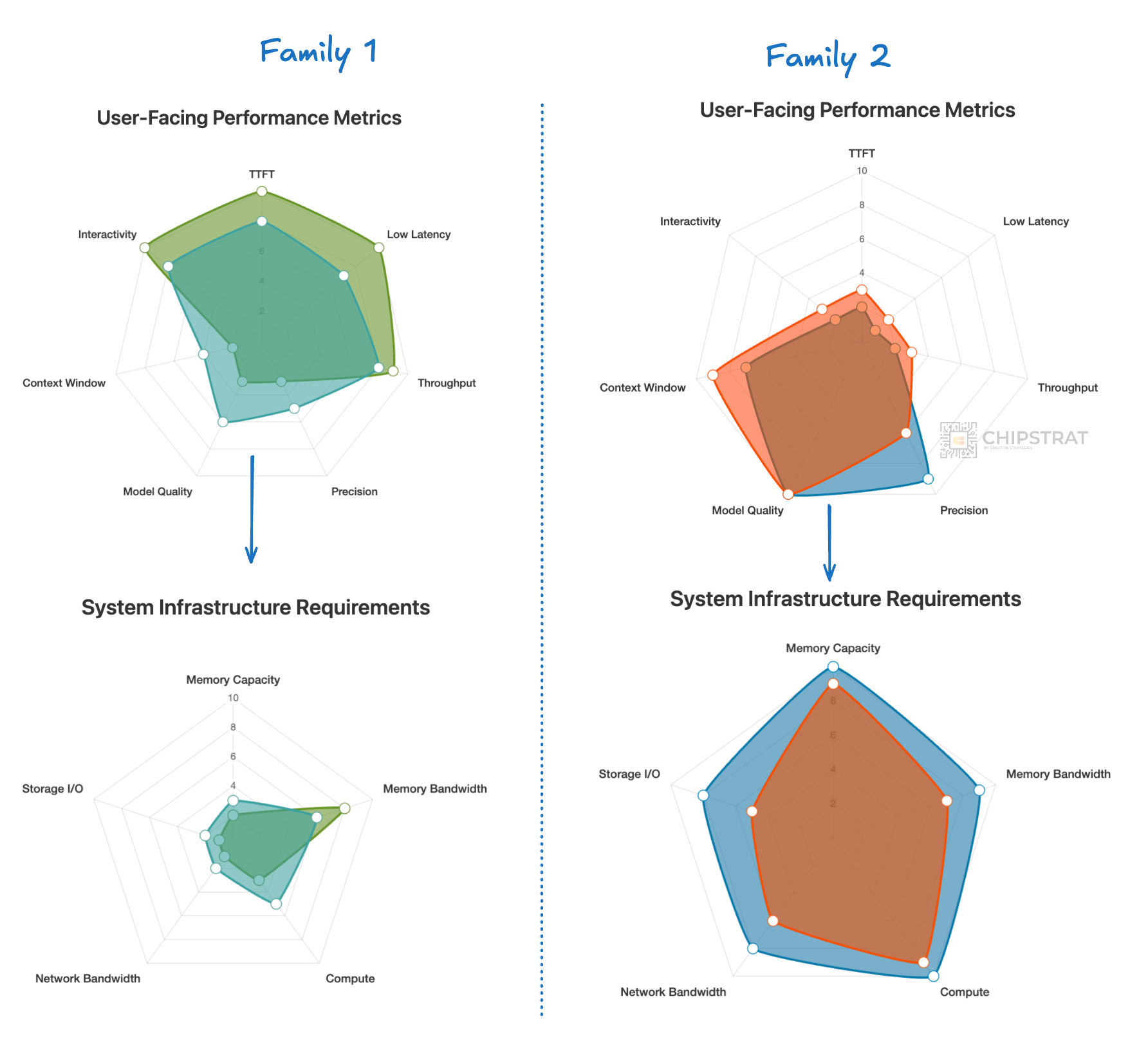
We already see this “right-sizing” of AI infra with disaggregating LLM inference across different Nvidia hardware; prefill on Rubin CPX and decode on traditional Rubin.
This line of thinking can lead to XPUs; if a particular hyperscaler is quite convinced they’ll need to run a particular type of workload at scale indefinitely, why not trade-off some of the flexibility of GPUs for a more finely tuned AI accelerator?
For example, won’t OpenAI continue to run fast-thinking (GPT-4o style) LLMs indefinitely?
For workloads that might continue to evolve significantly, stick with GPU-based clusters. But for stable workloads at the massive scale of hyperscalers, a custom AI cluster with XPUs can make sense. It’s been three years since ChatGPT launched already…
But customizing the datacenter to a particular workloads is more than just picking a particular already-baked chip. Just like Nvidia systems are GPUs + networking + software (+ memory, + CPUs, + storage), XPU-based systems also include networking, memory, and more. Marvell calls these additional components XPU attach.
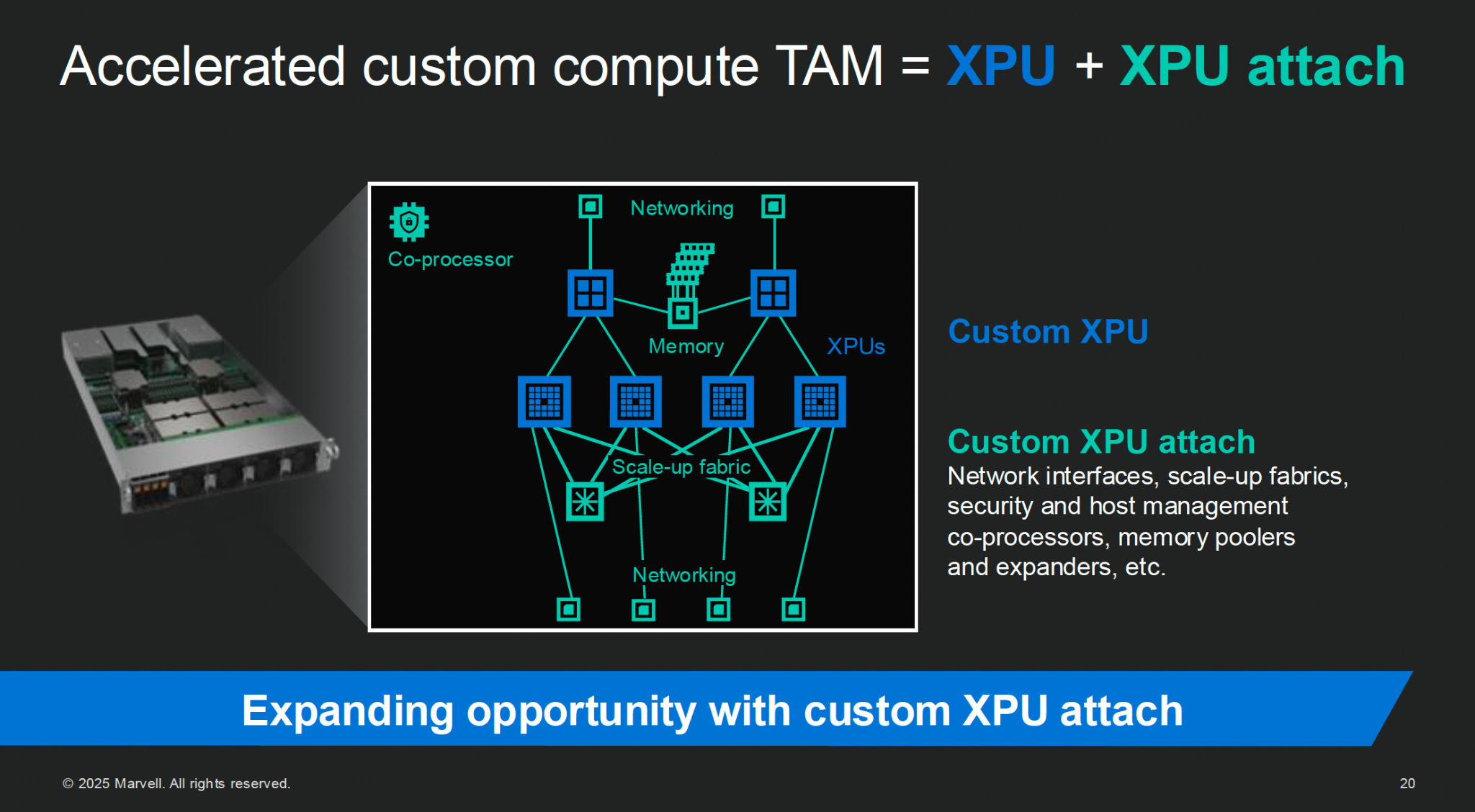
And with a custom accelerator partner you can turn all sorts of knobs deep within the XPU and XPU attach to tune the resulting AI datacenter to meet your workload’s needs.
Marvell’s Sandeep Bharathi: Now, Matt talked about XPU and XPU attach. What is important to see in an XPU attach, there may be certain IPs that are not necessary, for example, CPU. But what it means that for each of these, the power and performance per watt requirements are different, which means you need to optimize different SerDes or different Die-to-Dies (D2Ds) for each one of these to meet the needs of the workloads.
So customization to achieve the highest performance per watt is a Marvell specialty.
So IP building blocks like SerDes or D2D can be optimized to help the system get the needed system-level performance per Watt.
But….. what the heck is
...This excerpt is provided for preview purposes. Full article content is available on the original publication.