A real-life framework for RAG evaluation: beyond the 'Looks-Good-to-Me' Metric
Evaluation of RAG systems might seem straightforward in theory, but in practice it's one of the most challenging aspects of building generative AI systems, especially in real-world applications like customer support where data is noisy. Many discussions on RAG evaluation center around two primary components:
Retrieval Accuracy – Measuring the percentage of times the system retrieves the correct context required to answer a given question.
Generation Quality – Assessing the correctness and relevance of generated responses, usually with another LLM as a judge.
However, considering that questions asked by customers are very diversified and the source of knowledge can come from not standard data sources (link do click&create), implementation is far from trivial. That is why it is tempting to rely on a "looks-good-to-me" evaluation metric, which is subjective, inconsistent, and leads to misleading conclusions. Instead, a structured approach to RAG evaluation must be adopted, ensuring rigorous testing and validation before the system is deployed.
To be honest, if the team does not want to spend time on developing a solid evaluation framework, I do not want to work on a project. I have seen it many times so far and learnt from my mistake - without proper evaluation you enter a vicious circle of never-ending improvements without a clear understanding of the usefulness of the system. No, thank you.
In this article I am proposing a framework which is:
down to earth
considers the specifics of your data
and is time boxed so you can propose a concrete way forward for your team and have other stakeholders on board.
By following this five-week structured approach—three weeks for experimentation, two weeks for dataset creation, and one week for judge calibration—we ensure that we build a reliable and scalable evaluation framework. This is the way to move beyond the flawed "looks-good-to-me" metric and towards a robust, production-ready RAG system.
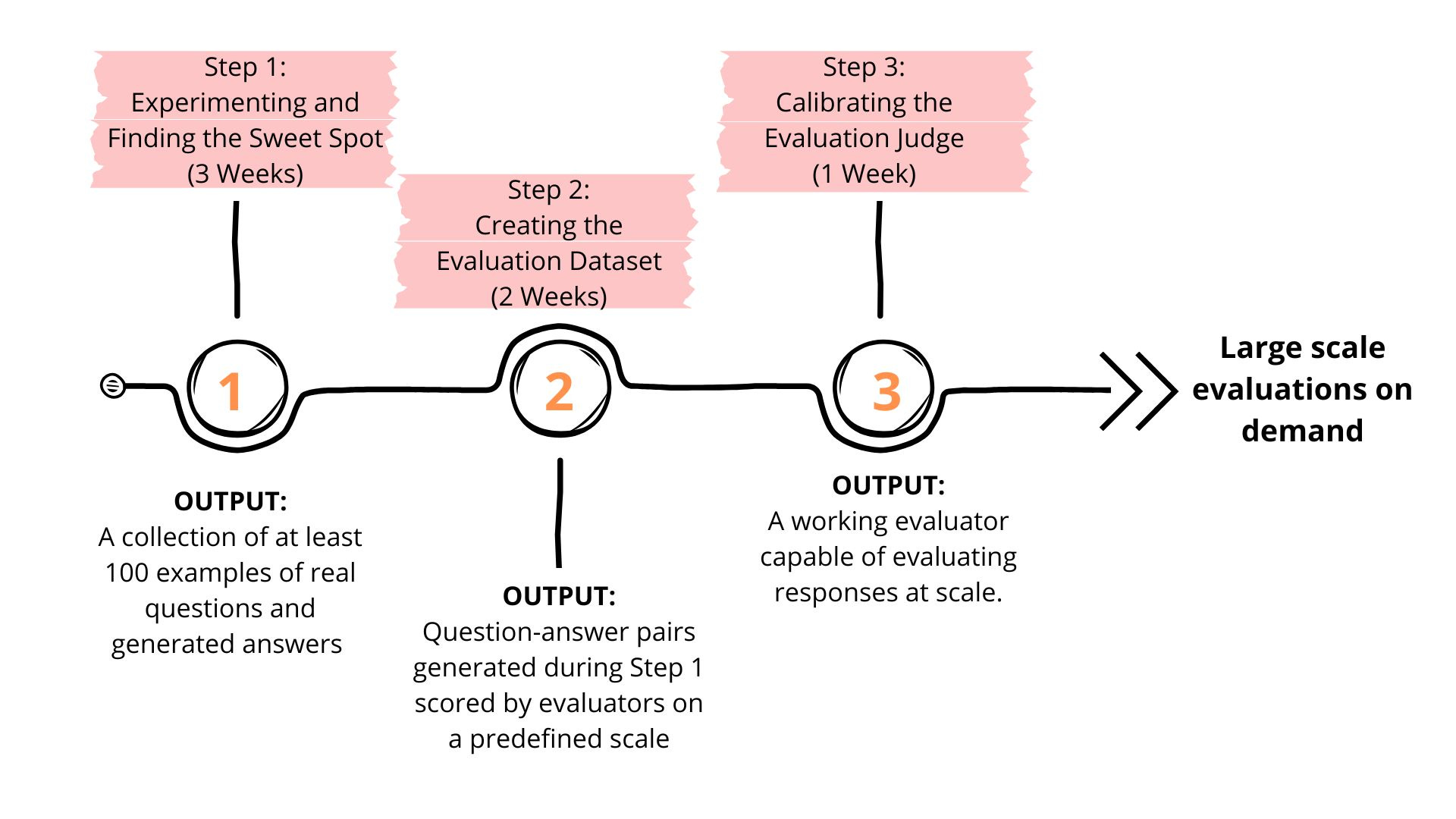
Step 1: Experimenting and Finding the Sweet Spot (3 Weeks)
Before conducting a formal evaluation, technical teams should experiment with various configurations to establish a baseline level of acceptable performance. The outputs from this phase are not intended to be production-ready. The primary goal is to generate results that can be reviewed by the evaluation team, allowing them to assess response quality. Since you will be "training" your evaluator on these responses, it's crucial to present a diverse range of questions.
During this stage it is critical to avoid presenting
...This excerpt is provided for preview purposes. Full article content is available on the original publication.