The article discusses how TPUs are based on systolic arrays from Kung and Leiserson's 1978 paper - understanding this fundamental architecture explains why TPUs are efficient for matrix multiplication
TPU v2 introduced bfloat16 for matrix multiplication - this specialized number format is crucial to understanding why AI accelerators can be more efficient than general-purpose chips
Nobel Prize winning economist, Paul Krugman, discusses TPUs and GPUs with Paul Kedrosky. No criticism of Krugman intended, it’s great that computer architecture is getting so much attention.
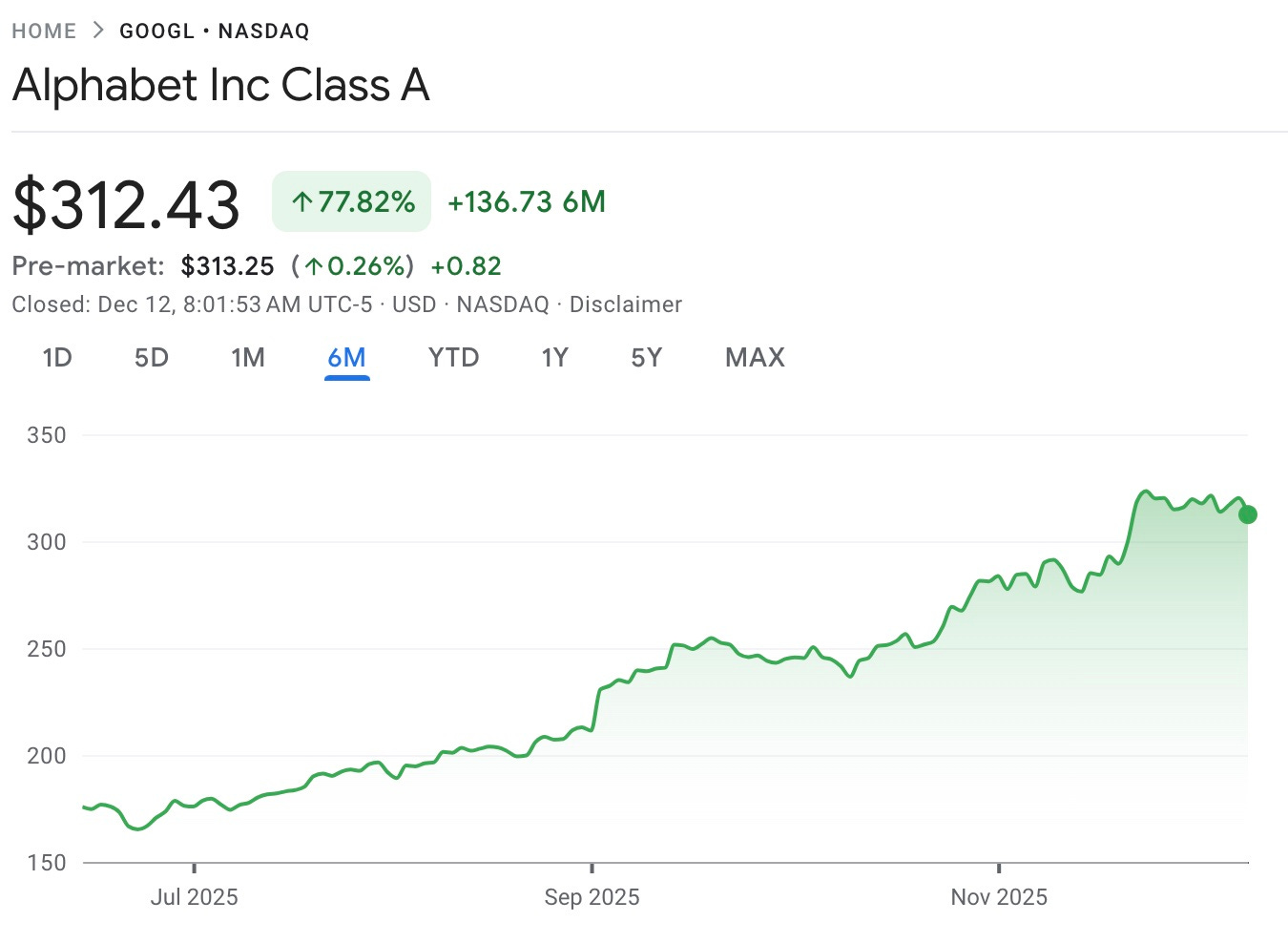
All of a sudden, everyone is talking - and writing - about Google’s TPUs (Tensor Processing Units). The use of TPUs to train Google latest, market leading Gemini 3 model together with Google’s decision to sell TPUs to third parties (apparently including arch-rival Meta) have combined to create a major ‘vibe-shift’ away from Nvidia and towards Google’s hardware.
Not just a vibe-shift either as Alphabet’s stock price has been on a tear:
The coverage of the latest TPUs (v7) has been so extensive that, rather than add another series of takes, I thought it would more useful for readers to curate a selection of some of the most informative posts and links on TPUv7.
Before that, though, I wanted to briefly highlight several points that I can’t recall seeing much discussed elsewhere.
A Twelve Year Overnight Success
We looked at the origins of Google’s TPU programme in:
The origins of the TPU program date Google date all the way back to 2013 - almost a decade before the launch of ChatGPT - when it first became apparent that Google might need to start applying deep learning at scale.
The essence of the design dates back even further - into the 1970s. In their 1978 paper Systolic Arrays (for VLSI) H.T Kung and Charles E. Leiserson of Carnegie Mellon University had set out proposals for what they called a ‘systolic system’.
A systolic system is a network of processors which rhythmically compute and pass data through the system….In a systolic computer system, the function of a processor is analogous to that of the heart. Every processor regularly pumps data in and out, each time performing some short computation so that a regular flow of data is kept up in the network.
The approach didn’t gain widespread adoption in the 1970s and 1980s, but by 2013 the time was right:
By 2013 some of the original motivation behind Kung and Lieberson’s ideas had fallen away, particularly dealing with the limits of fabrication technology of the 1970s, had fallen away. However, the inherent efficiency, and of particular relevance in 2013, the relatively low power consumption, of this approach for tasks such as matrix multiplication remained. So the TPU would use systolic arrays.