Role of Storage in AI, Primer on NAND Flash, and Deep-Dive into QLC SSDs
Welcome to a 🔒 subscriber-only deep-dive edition 🔒 of my weekly newsletter. Each week, I help investors, professionals and students stay up-to-date on complex topics, and navigate the semiconductor industry.
If you’re new, start here. As a paid subscriber, you will get additional in-depth content. See here for all the benefits of upgrading your subscription tier!
Note to paid subscribers: This post is long, and to save you time, here is an executive summary post. Thanks for all your support! I still recommend reading the full post for a comprehensive understanding.
I have a video version, if you want to understand the fundamentals of NAND flash!
A lot of attention is given to compute, memory and networking in an AI data center - from how quickly GPUs get data from HBM, to how fast the interconnects in a datacenter are. What gets less attention is the design of high capacity storage for AI workloads.
Frontier models are trained on tens of trillions of tokens, which typically occupy multiple terabytes of training data depending on the precision format used. During the training process, voluminous amounts of data need to be delivered to the GPU on time for computation because underutilizing GPU time quickly adds to model training costs.
The storage demands on the inference side are even higher. With 800 million ChatGPT users and counting, all the queries, documents, images, and videos generated or uploaded need to be stored somewhere, and query results must be generated in a matter of milliseconds, or a few seconds at most. This requires in the range of 50-100 petabytes (1 PB = 1,000 TB) in a single storage rack.
All these workloads require fast access to high capacity storage, which is present as local SSDs within the compute tray, networked SSDs in a storage server connected over fabrics like Ethernet/Infiniband, or just massive clusters of HDDs for long term archival as shown in the picture below.
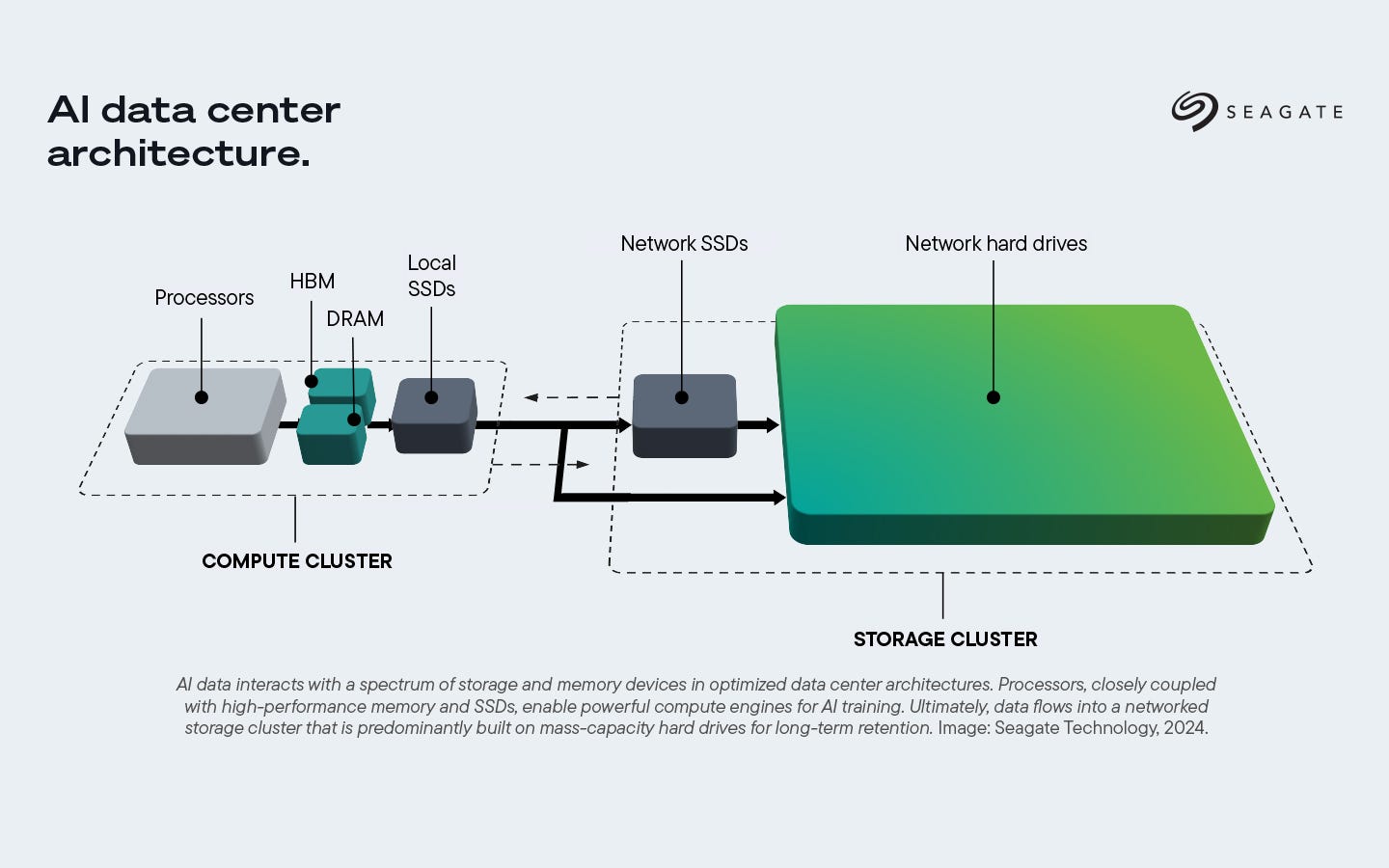
In this article, we will look at how data flows during training and inference, understand storage hierarchies in a datacenter, develop a thorough understanding of NAND flash technologies, and discuss emerging QLC NAND flash in quite some detail.
For free subscribers:
Role of Storage in LLMs: How the interplay between HBM and SSDs is essential to training and inference.
Storage hierarchy in AI datacenters: Understanding the cost, capacity and speed constraints of various
This excerpt is provided for preview purposes. Full article content is available on the original publication.