Graph RAG in Customer Service - beyond the buzz (Part 1: Community Summaries)
Graph RAGs are all the rage now. From the business perspective, they hold the potential to enhance the quality of traditional RAG systems, delivering more accurate and contextually relevant answers to users. However, how this would work in real-world settings remains unclear. During our investigation, we found that most articles and tutorials on the subject were vague. The examples provided were often generic (“Paris IS_A city”) rather than demonstrating concrete benefits over traditional RAG systems through case studies. In this post, I provide observations based on experiments on real customer support data.
The theory of Graph RAG seems promising, especially given that we’re working on technical customer support. Our systems are usually based on documentations, manuals and blogposts, in particular about electronic devices. Such data has a deep structural logic of how the devices work, regarding both their internal construction and cooperation with other systems. So, a graph structure seems like a logical choice.
Graph RAG systems are quite complex, but the main idea is to detect entities and their relationships in text chunks. This allows to build an interconnected structure (a graph), where some entities (and by proxy, their corresponding chunks) are more strongly connected than others, building communities. Community detection is done using classic graph algorithms such as Leiden algorithm. After detection, it is possible to summarize the contents of each community using an LLM. The Community Summaries are an important feature of a Graph RAG retrieval system (however, in a full-blown Graph RAG, they are just one of many multi-level sources of information).
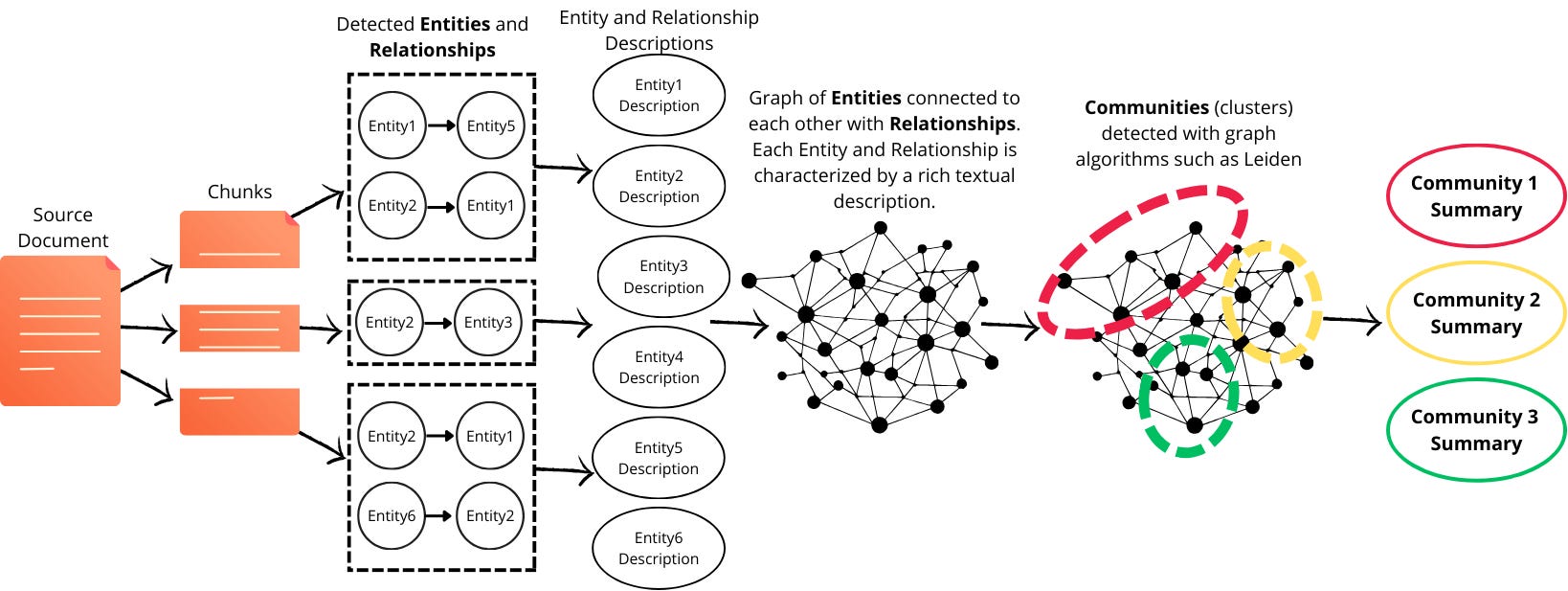
In this post, I focus specifically on Community Summaries and their potential role in a technical customer support RAG system. What unique value can they provide compared to a traditional RAG? Can they uncover insights that a standard RAG system cannot?
Although I observed some promising results, we don’t have such a system in production. We need more data to determine whether these improvements will be consistently achievable—particularly when factoring in the increased processing costs associated with Graph RAG systems.
Technical setting
I use a basic Graph RAG setup with LlamaIndex, similar to the one described in the post: https://docs.llamaindex.ai/en/stable/examples/cookbooks/GraphRAG_v1/
I chose to experiment with LlamaIndex primarily because “pro” graph databases like Neo4j often come with a steep learning curve for many AI practitioners. While LlamaIndex offers only basic support for Graph RAGs, it is sufficient for studying graph communities. However, it currently lacks
...This excerpt is provided for preview purposes. Full article content is available on the original publication.