Quantizing Olmo 3: Most Efficient and Accurate Formats
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Quantization (signal processing)
13 min read
The article focuses on quantizing neural network weights to different bit formats (INT8, FP8, NVF4). Understanding the mathematical foundations of quantization—how continuous values are mapped to discrete levels and the tradeoffs involved—provides essential context for why these techniques reduce model size while potentially sacrificing accuracy.
-
Reinforcement learning from human feedback
13 min read
The article mentions Olmo 3's training pipeline includes DPO (Direct Preference Optimization) and RL stages. RLHF is the foundational technique that these methods build upon, explaining how language models are aligned to human preferences through reward modeling and policy optimization.
-
Floating-point arithmetic
7 min read
The quantization formats discussed (fp8-dynamic, nvfp4, w4a16) all involve different floating-point representations. Understanding how floating-point numbers work—mantissa, exponent, precision tradeoffs—helps readers grasp why FP8 and FP4 formats can approximate full-precision weights with significant memory savings.
Quantizing Olmo 3: Most Efficient and Accurate Formats
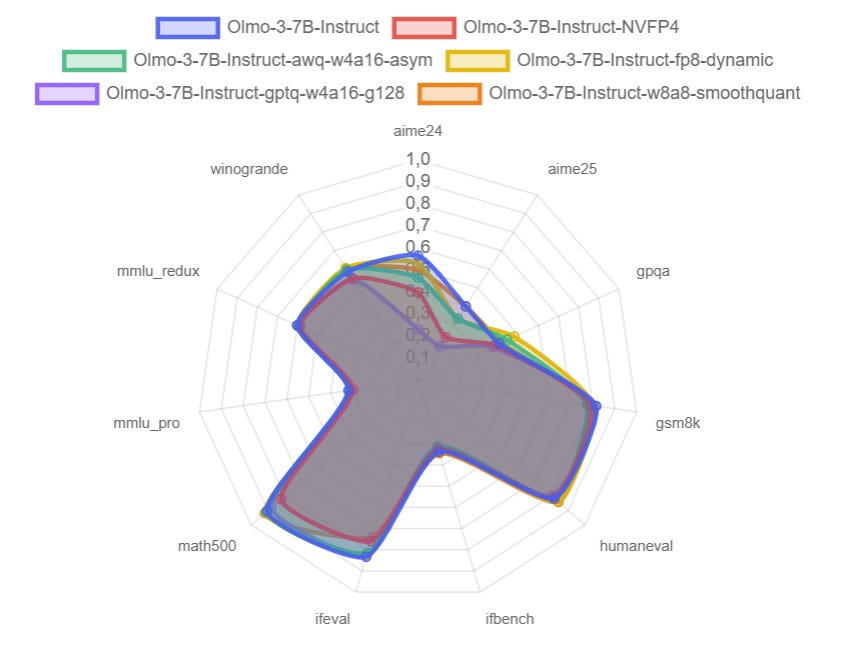
Olmo 3 is a standard 7B/32B decoder-only transformer. No MoE, no exotic attention, no flashy new architecture tricks. Most of the change is in the training pipeline: in the data (Dolma 3), the midtraining mix (Dolmino), the long-context stage (Longmino), and the “thinking” stack (Dolci, SFT, DPO, RL).
In this article, I briefly go through what actually changed compared to Olmo 2, and what didn’t work.
Then I move to quantization. I quantized Olmo 3 7B and 32B with several standard recipes that are practical to run on a single consumer GPU:
gptq-w4a16-g128
fp8-dynamic
nvfp4
awq with custom mappings for Olmo 3
W8A8 (INT8) with SmoothQuant
Finally, I look at how these variants behave on benchmarks: accuracy, PASS@k, and token efficiency, plus some notes on hardware choices (RTX 5090 vs RTX 6000) and what actually matters once you run long contexts with concurrent queries.
I used the same quantization script I released last week:
I released my quantized models here:
This excerpt is provided for preview purposes. Full article content is available on the original publication.