How Grab Built a Vision LLM to Scan Images
Kubernetes Quick-Start Guide (Sponsored)

Cut through the noise with this engineer-friendly guide to Kubernetes observability. Save this reference for fast-track access to essential kubectl commands and critical metrics, from disk I/O and network latency to real-time cluster events. Perfect for scaling, debugging, and tuning your workloads without sifting through endless docs.
Digital services require accurate extraction of information from user-submitted documents such as identification cards, driver’s licenses, and vehicle registration certificates. This process is essential for electronic know-your-customer (eKYC) verification. However, the diversity of languages and document formats across the region makes this task particularly challenging.
Grab Engineering Team faced significant obstacles with traditional Optical Character Recognition (OCR) systems, which struggled to handle the variety of document templates. While powerful proprietary Large Language Models (LLMs) were available, they often failed to adequately understand Southeast Asian languages, produced errors and hallucinations, and suffered from high latency. Open-source Vision LLMs offered better efficiency but lacked the accuracy required for production deployment.
This situation prompted Grab to fine-tune existing models and eventually build a lightweight, specialized Vision LLM from the ground up. In this article, we will look at the complete architecture, the technical decisions made, and the results achieved.
Disclaimer: This post is based on publicly shared details from the Grab Engineering Team. Please comment if you notice any inaccuracies.
Understanding Vision LLMs
Before diving into the solution, it helps to understand what a Vision LLM is and how it differs from traditional text-based language models.
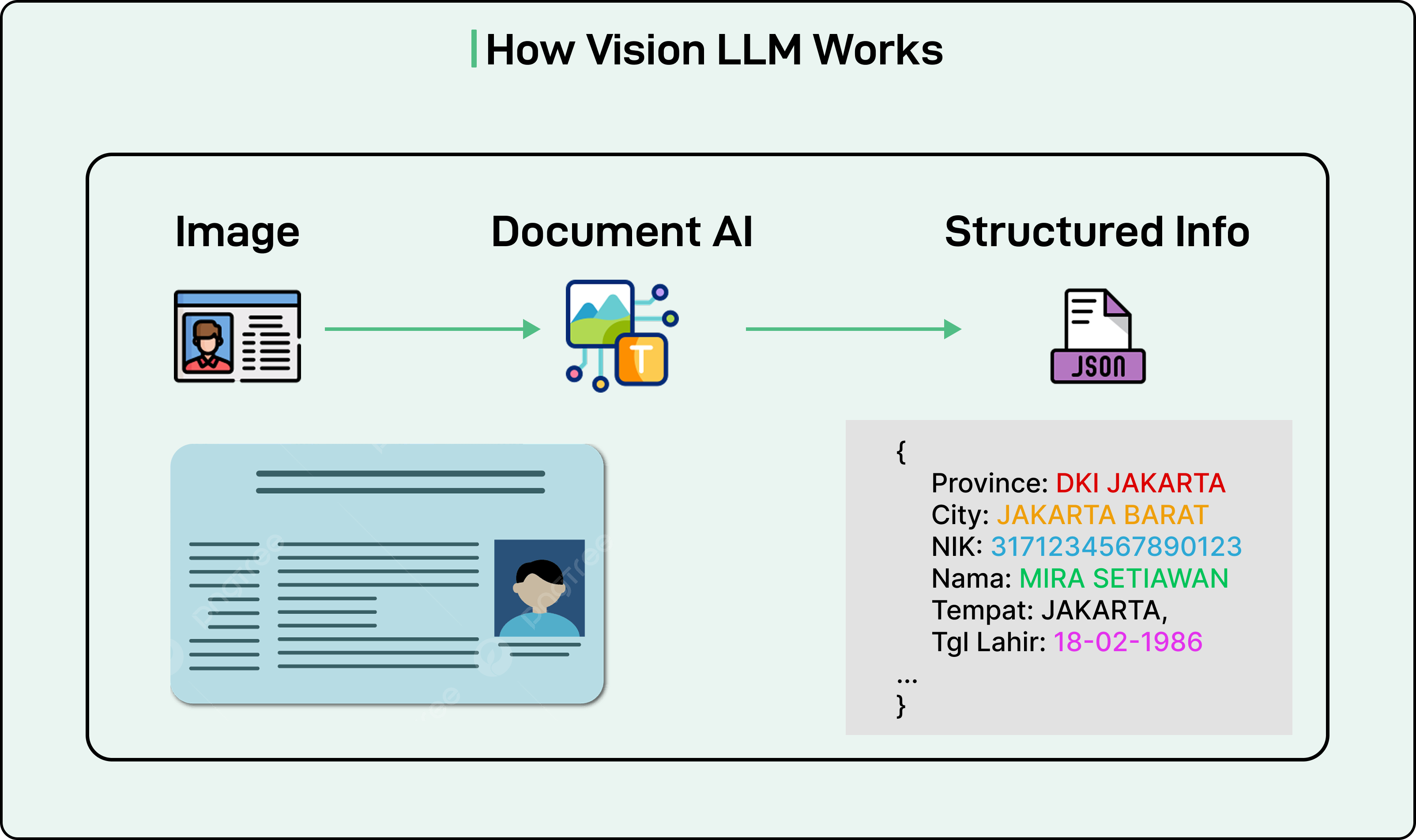
A standard LLM processes text inputs and generates text outputs. A Vision LLM extends this capability by enabling the model to understand and process images. The architecture consists of three essential components working together:
The first component is the image encoder. This module processes an image and converts it into a numerical format that computers can work with. Think of it as translating visual information into a structured representation of numbers and vectors.
The second component is the vision-language projector. This acts as a bridge between the image encoder and the language model. It transforms the numerical representation of the image into a format that the language model can interpret and use alongside text inputs.
The third component is the language model itself. This is the familiar text-processing model that takes both the transformed image information and any text instructions to generate a final text output. In the case of document processing,
This excerpt is provided for preview purposes. Full article content is available on the original publication.