GPU Networking, Part 4: Year End Wrap
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Exascale computing
12 min read
The article mentions that NVL72 achieves 1.4 exaFLOPS and notes that the world's largest supercomputer only recently achieved an exaFLOP. Understanding the history and technical challenges of exascale computing provides crucial context for appreciating why Nvidia's achievement is significant.
-
High Bandwidth Memory
9 min read
HBM is central to the article's explanation of why scale-up networking exists - GPU memory capacity can't keep up with model size growth. Understanding HBM's architecture, stacking technology, and bandwidth characteristics would help readers grasp the fundamental constraint driving these networking innovations.
-
Non-uniform memory access
11 min read
The article's core concept of making 'remote HBM feel as close to local memory as possible' is essentially describing NUMA architecture principles applied to GPU clusters. Understanding NUMA provides the theoretical foundation for why latency matters so much in scale-up networking.
As 2025 comes to a close, let’s check in on the current state of the AI networking ecosystem. We’ll touch on Nvidia, Broadcom, Marvell, AMD, Arista, Cisco, Astera Labs, Credo. Can’t get to everyone, so we’ll hit on more names next year (Ayar Labs, Coherent, Lumentum, etc).
We’ll look at NVLink vs UALink vs ESUN. And I’ll explain the rationale behind UALoE.
We’ll talk optical, AECs, and copper.
It’ll be comprehensive. 6000 or so words, with 70% behind the paywall since I spent a really long time on this :)
I’ll even toss in some related sell-side commentary.
But first, a quick refresher on scale-up, scale-out, and scale-across. There’s still some confusion out there.
Scale Up, Scale Out, Scale Across
AI networking is mostly about moving data and coordinating work. The extremely parallel number crunchers (GPUs/XPUs) need to be fed data on time and in the right order.
Scale-up, scale-out, and scale-across are three architectural approaches to transmitting that information, each with very different design tradeoffs.
It’s important to understand the nuance of scale-up, so let’s start there.
BTW: I’ll use GPU and XPU interchangeably as a shorthand for AI accelerator.
Scale Up
GPUs have a fixed amount of high-bandwidth memory (HBM) per chip; that capacity is increasing over time, but it can’t keep up with the rapid increase in LLM size. It’s been a long time since frontier models fit into the memory of a single chip:
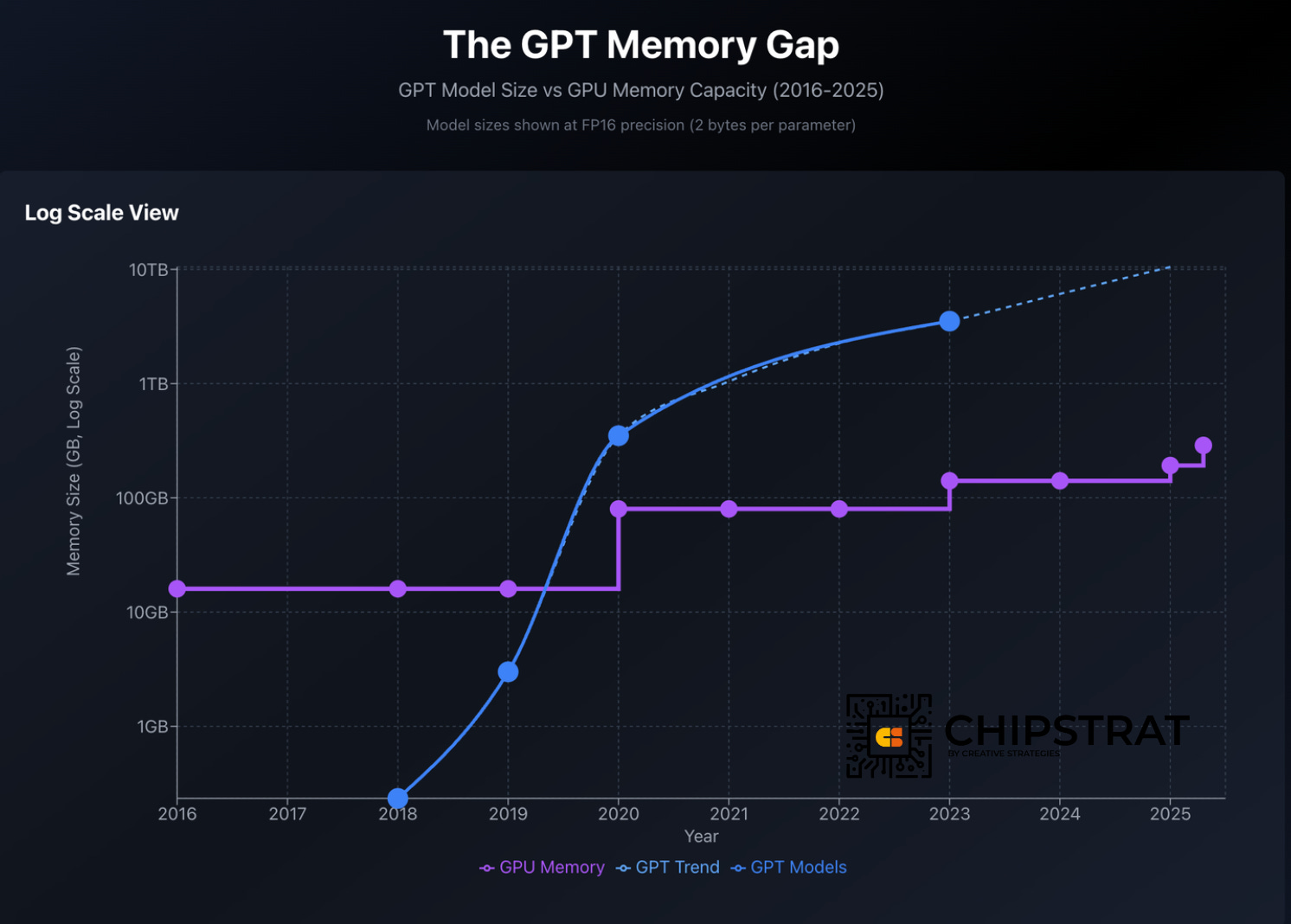
Once a model no longer fits in a single GPU’s HBM, the accelerator must fetch portions of the model from elsewhere. As there’s no nearby shared pool of HBM today, “elsewhere” means accessing HBM attached to other accelerators over a network, which is slower and less predictable than local memory.
But what if fetching memory from “elsewhere” could be made fast enough that the accelerator barely notices? That’s the motivation behind scale-up networking!
Scale-up pools memory across multiple GPUs so they behave like one larger logical device with a much bigger effective HBM footprint:
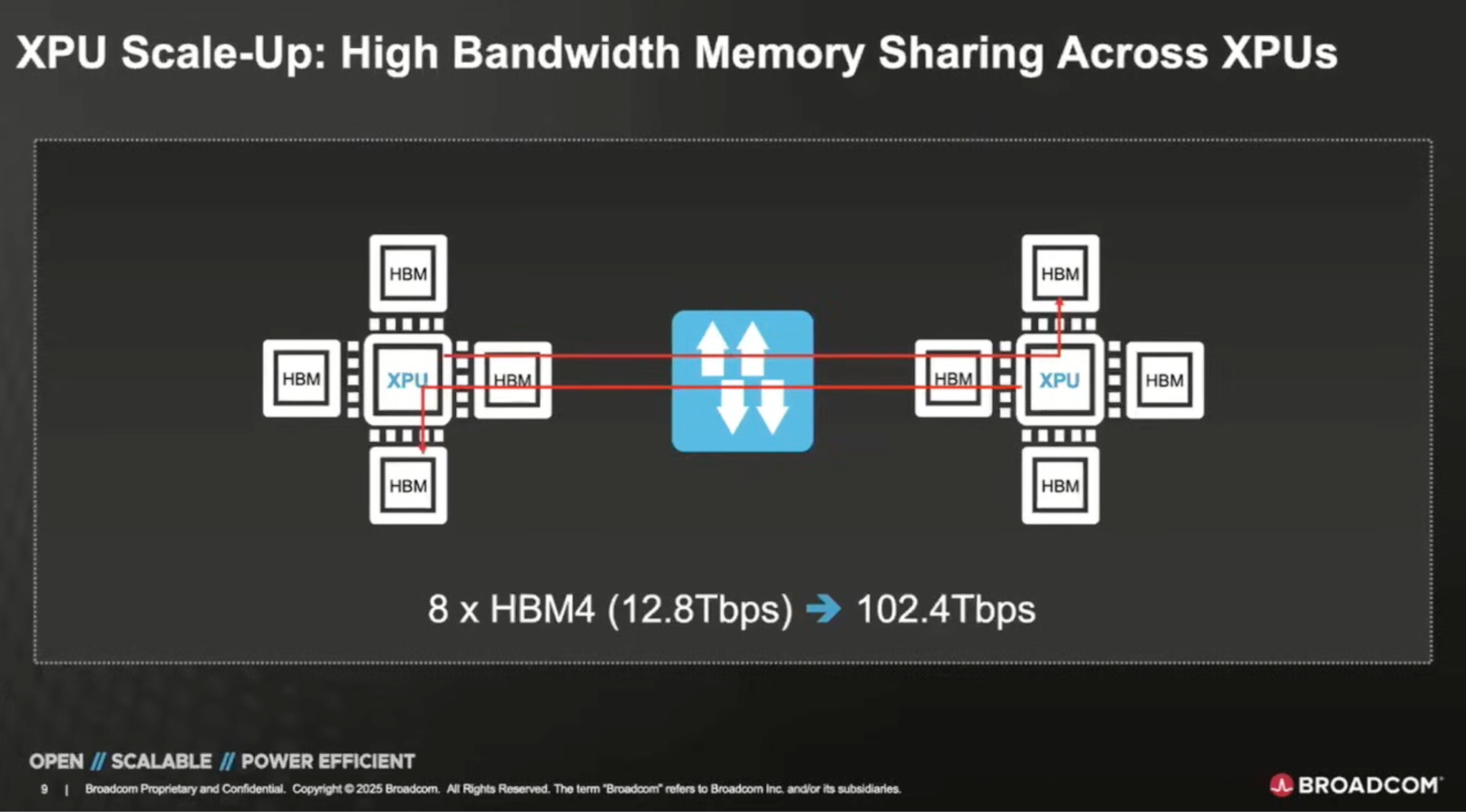
Pulling this illusion of locality off requires really fast interconnects; the goal is to make remote
...This excerpt is provided for preview purposes. Full article content is available on the original publication.