The Weekly Kaitchup #115

Hi Everyone,
In this edition of The Weekly Kaitchup:
Reproducible Evaluation with vLLM
The Unexpected Qwen3-VL 2B and 32B
Continual Fine-Tuning with Memory Layers: Fine-Tune Instruct/Heavily Post-trained Models without Destroying Them?
DeepSeek-OCR: Compression→Decompression of Text As Vision Tokens
Reproducible Evaluation with vLLM
Reproducible evaluation is the backbone of trustworthy AI research. If the same prompt yields different probabilities just because you changed the batch size or switched from single-request to batched execution, your comparisons become noisy and misleading. You can’t reliably A/B models, diagnose regressions, or share results if “run it again” changes the answer.
Historically, vLLM and most other inference frameworks, produced different results at different batch sizes. I did a few experiments to measure the impact of this almost a year ago. People said it was “normal.” Technically, sure. But scientifically, batch size should not affect evaluation. Sampling parameters and the random seed? Yes. Batch size? No.

So, I’m thrilled that vLLM now supports batch-invariant inference. Flip one switch, VLLM_BATCH_INVARIANT=1, and you get identical results whether you run batch size 1, batch size N, or prefill with generated tokens. No more divergences in logprobs between decode paths or prefill vs. prefill+decode. The probabilities sampled from the model are exactly the same across execution modes, making side-by-side evaluations and automated test suites dramatically more reliable. No more excuses: if you publish benchmark results, we should be able to reproduce them, even at batch size > 1.
The Unexpected Qwen3-VL 2B and 32B
I thought Qwen was done with Qwen3-VL after releasing 4B and 8B models. And I published a fine-tuning guide for Qwen3-VL, anticipating as “unlikely” the release of smaller models:
Well, I was wrong!
Qwen released 2B and 32B versions:
They perform well, but the 2B model appears much less useful than the 4B model, which already fits on many configurations.
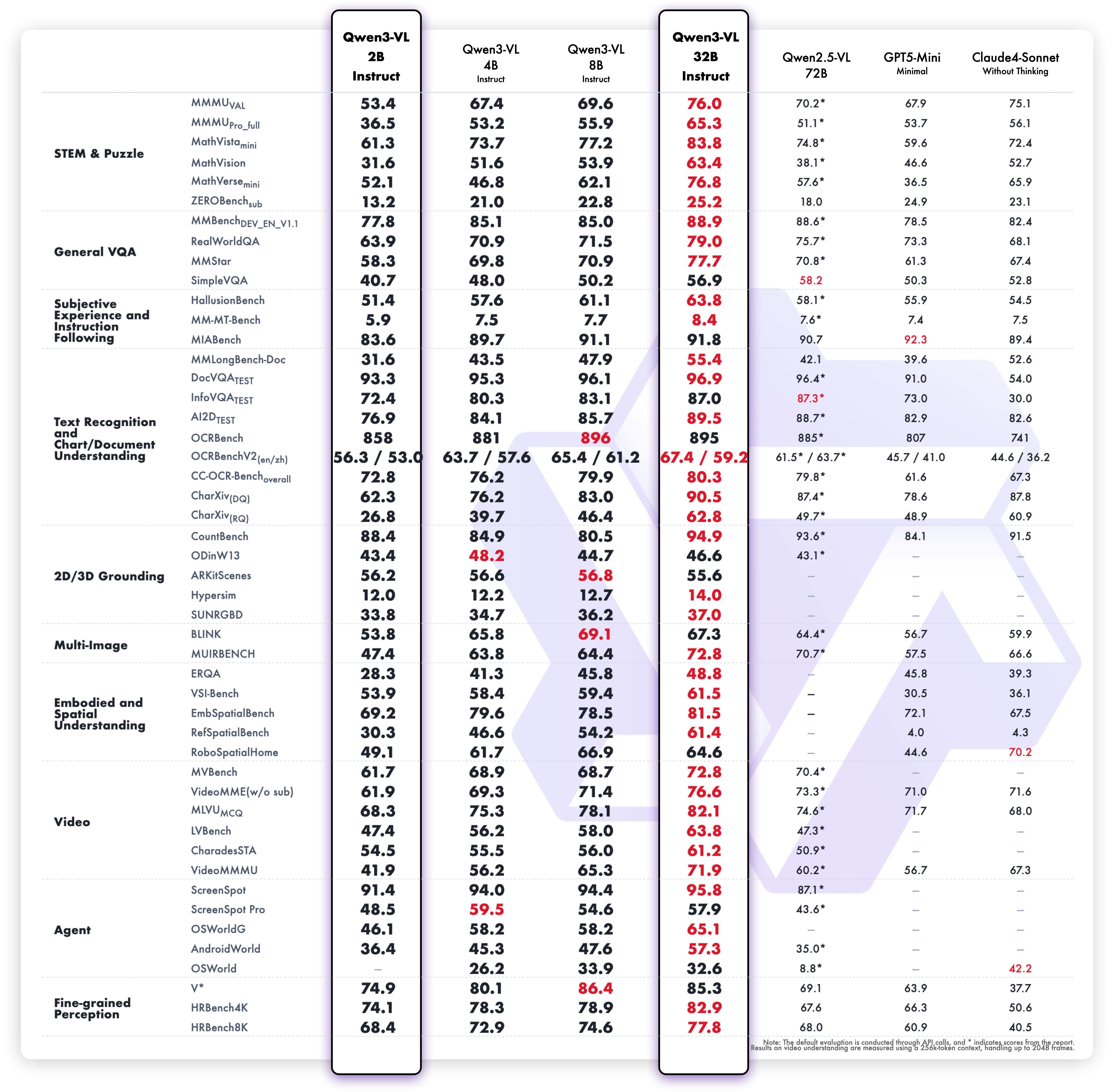
Is Qwen3-VL 32B better than Qwen3-VL 30B-A3B MoE?
Qwen doesn’t directly answer this question, but we can compare the results ourselves:
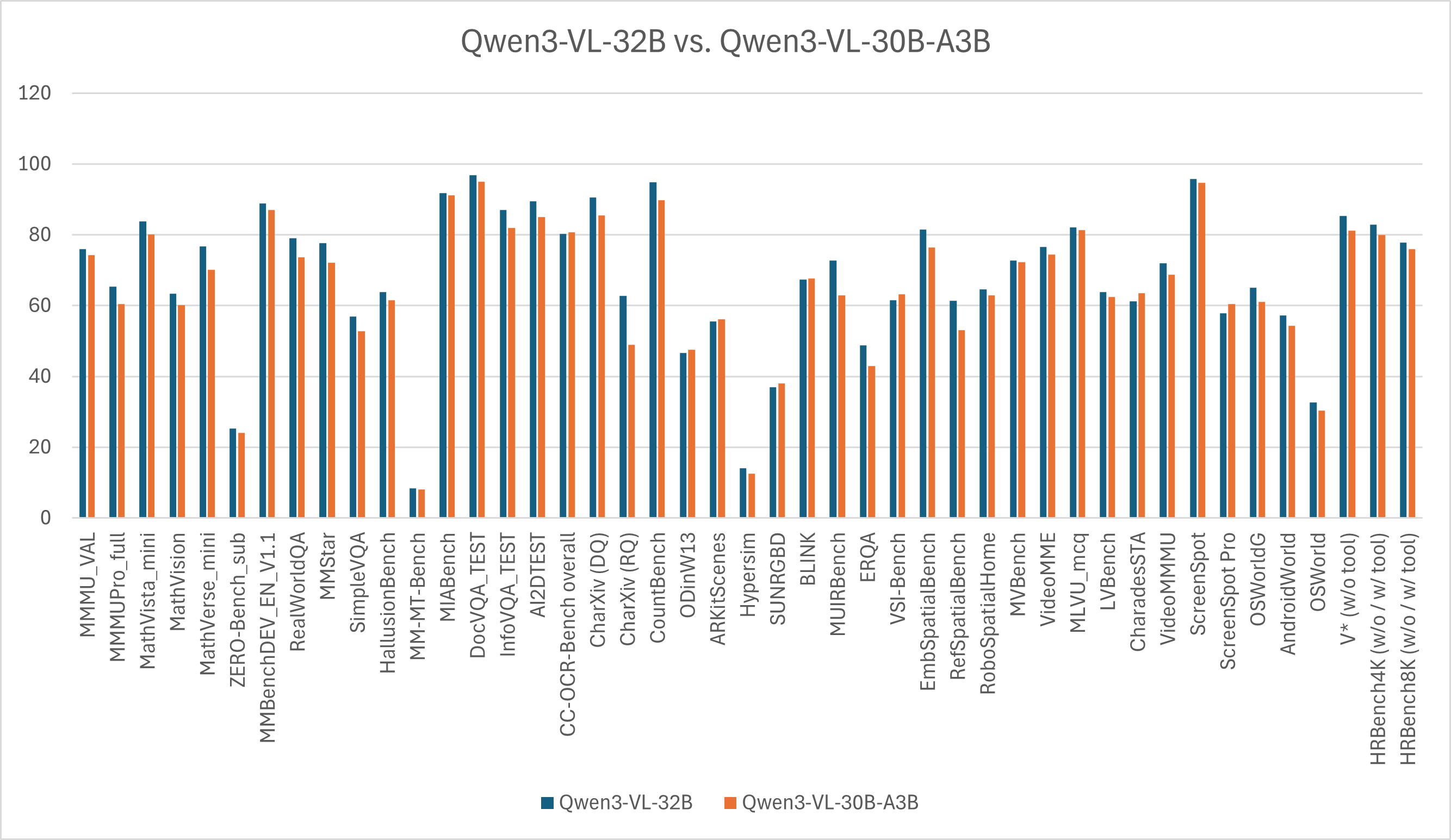
If you don’t care about the inference speed, the 32B version is significantly better while consuming almost the same memory.
Continual Fine-Tuning with Memory Layers: Fine-Tune Instruct/Heavily Post-trained Models without Destroying Them?
Training a model on your own data for narrow domains or tasks, while preserving the broad capabilities painstakingly instilled by the provider’s post-training, is
...This excerpt is provided for preview purposes. Full article content is available on the original publication.