Beyond Standard LLMs
From DeepSeek R1 to MiniMax-M2, the largest and most capable open-weight LLMs today remain autoregressive decoder-style transformers, which are built on flavors of the original multi-head attention mechanism.
However, we have also seen alternatives to standard LLMs popping up in recent years, from text diffusion models to the most recent linear attention hybrid architectures. Some of them are geared towards better efficiency, and others, like code world models, aim to improve modeling performance.
After I shared my Big LLM Architecture Comparison a few months ago, which focused on the main transformer-based LLMs, I received a lot of questions with respect to what I think about alternative approaches. (I also recently gave a short talk about that at the PyTorch Conference 2025, where I also promised attendees to follow up with a write-up of these alternative approaches). So here it is!
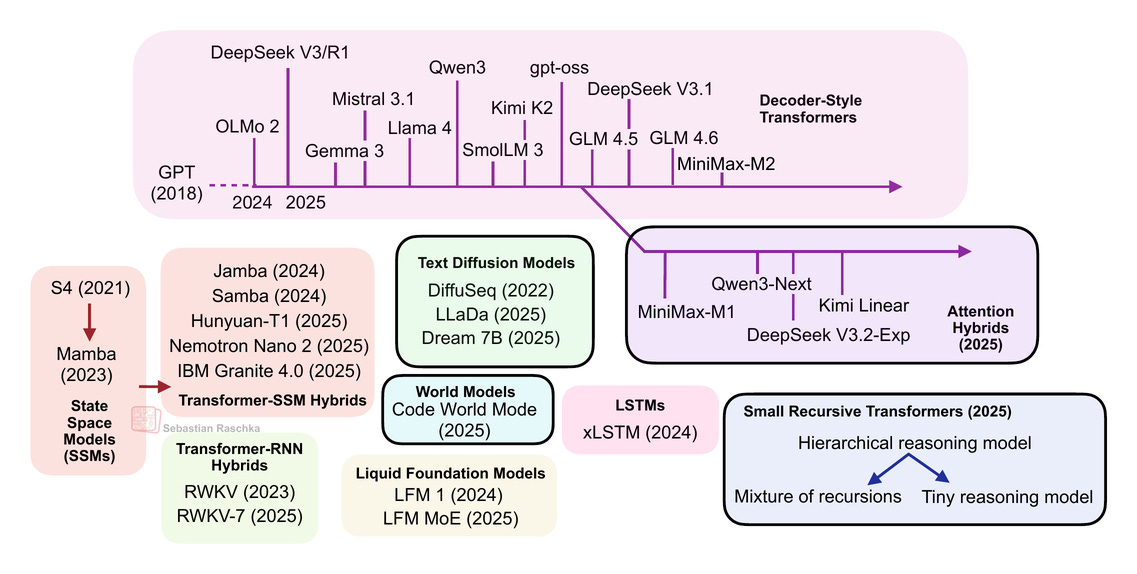
Note that ideally each of these topics shown in the figure above would deserve at least a whole article itself (and hopefully get it in the future). So, to keep this article at a reasonable length, many sections are reasonably short. However, I hope this article is still useful as an introduction to all the interesting LLM alternatives that emerged in recent years.
PS: The aforementioned PyTorch conference talk will be uploaded to the official PyTorch YouTube channel. In the meantime, if you are curious, you can find a practice recording version below.
(There is also a YouTube version here.)
1. Transformer-Based LLMs
Transformer-based LLMs based on the classic Attention Is All You Need architecture are still state-of-the-art across text and code. If we just consider some of the highlights from late 2024 to today, notable models include
DeepSeek V3/R1
OLMo 2
Gemma 3
Mistral Small 3.1
Llama 4
Qwen3
SmolLM3
Kimi K2
gpt-oss
GLM-4.5
GLM-4.6
MiniMax-M2
and many more.
(The list above focuses on the open-weight models; there are proprietary models like GPT-5, Grok 4, Gemini 2.5, etc. that also fall into this category.)
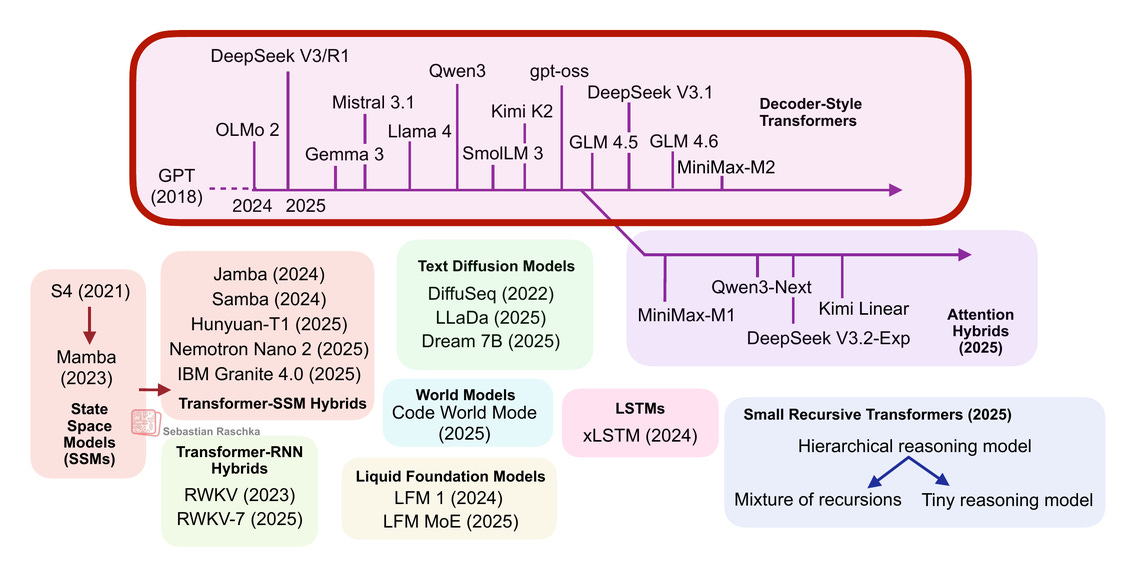
Since I talked and wrote about transformer-based LLMs so many times, I assume you are familiar with the broad idea and
...This excerpt is provided for preview purposes. Full article content is available on the original publication.