How Transformers Architecture Powers Modern LLMs
Why context engines matter more than models in 2026 (Sponsored)

One of the clearest AI predictions for 2026: models won’t be the bottleneck—context will. As AI agents pull from vector stores, session state, long-term memory, SQL, and more, finding the right data becomes the hard part. Miss critical context and responses fall apart. Send too much and latency and costs spike.
Context engines emerge as the fix. A single layer to store, index, and serve structured and unstructured data, across short- and long-term memory. The result: faster responses, lower costs, and AI apps that actually work in production.
When we interact with modern large language models like GPT, Claude, or Gemini, we are witnessing a process fundamentally different from how humans form sentences. While we naturally construct thoughts and convert them into words, LLMs operate through a cyclical conversion process.
Understanding this process reveals both the capabilities and limitations of these powerful systems.
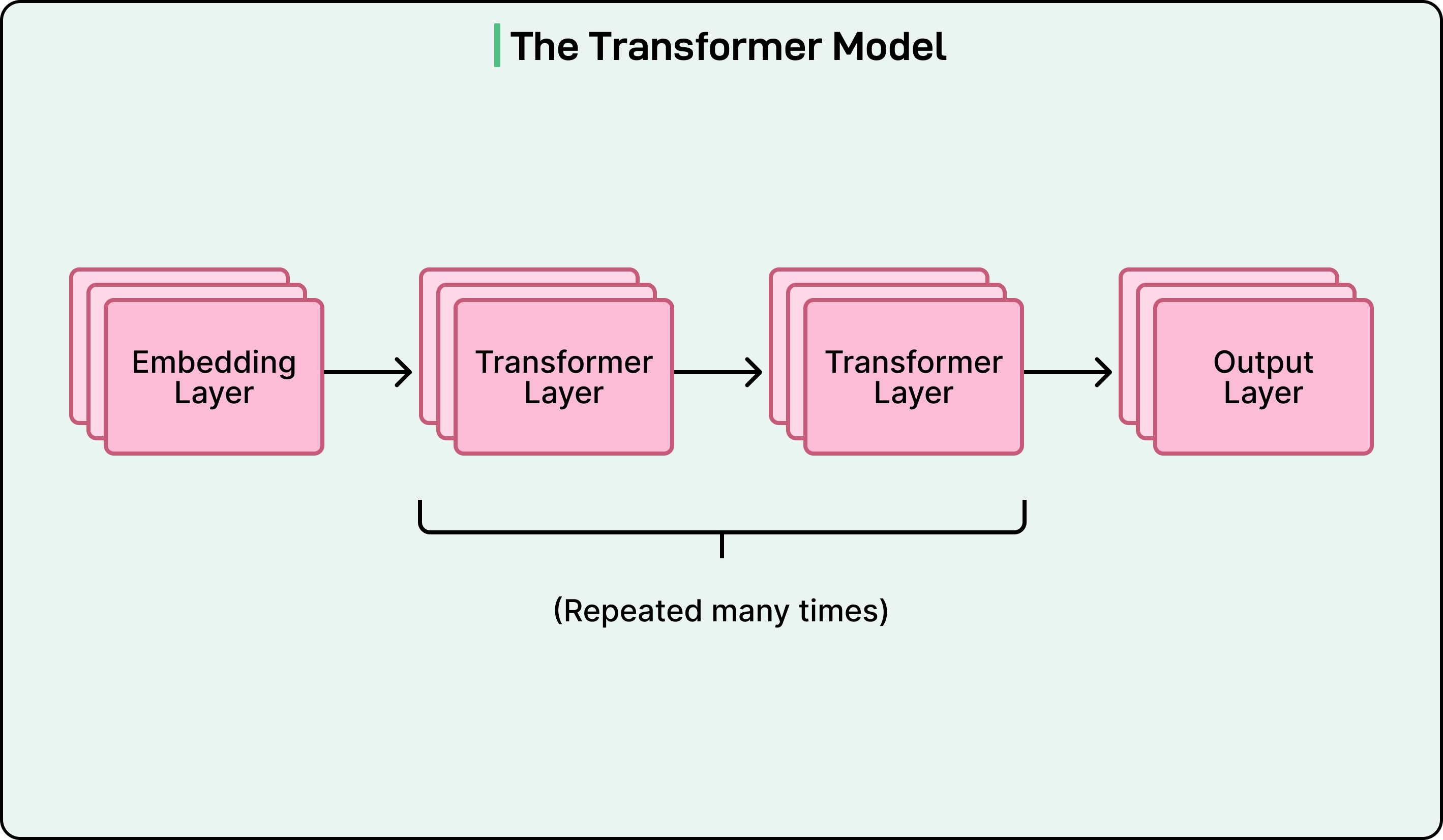
At the heart of most modern LLMs lies an architecture called a transformer. Introduced in 2017, transformers are sequence prediction algorithms built from neural network layers. The architecture has three essential components:
An embedding layer that converts tokens into numerical representations.
Multiple transformer layers where computation happens.
Output layer that converts results back into text.
See the diagram below:
Transformers process all words simultaneously rather than one at a time, enabling them to learn from massive text datasets and capture complex word relationships.
In this article, we will look at how the transformer architecture works in a step-by-step manner.
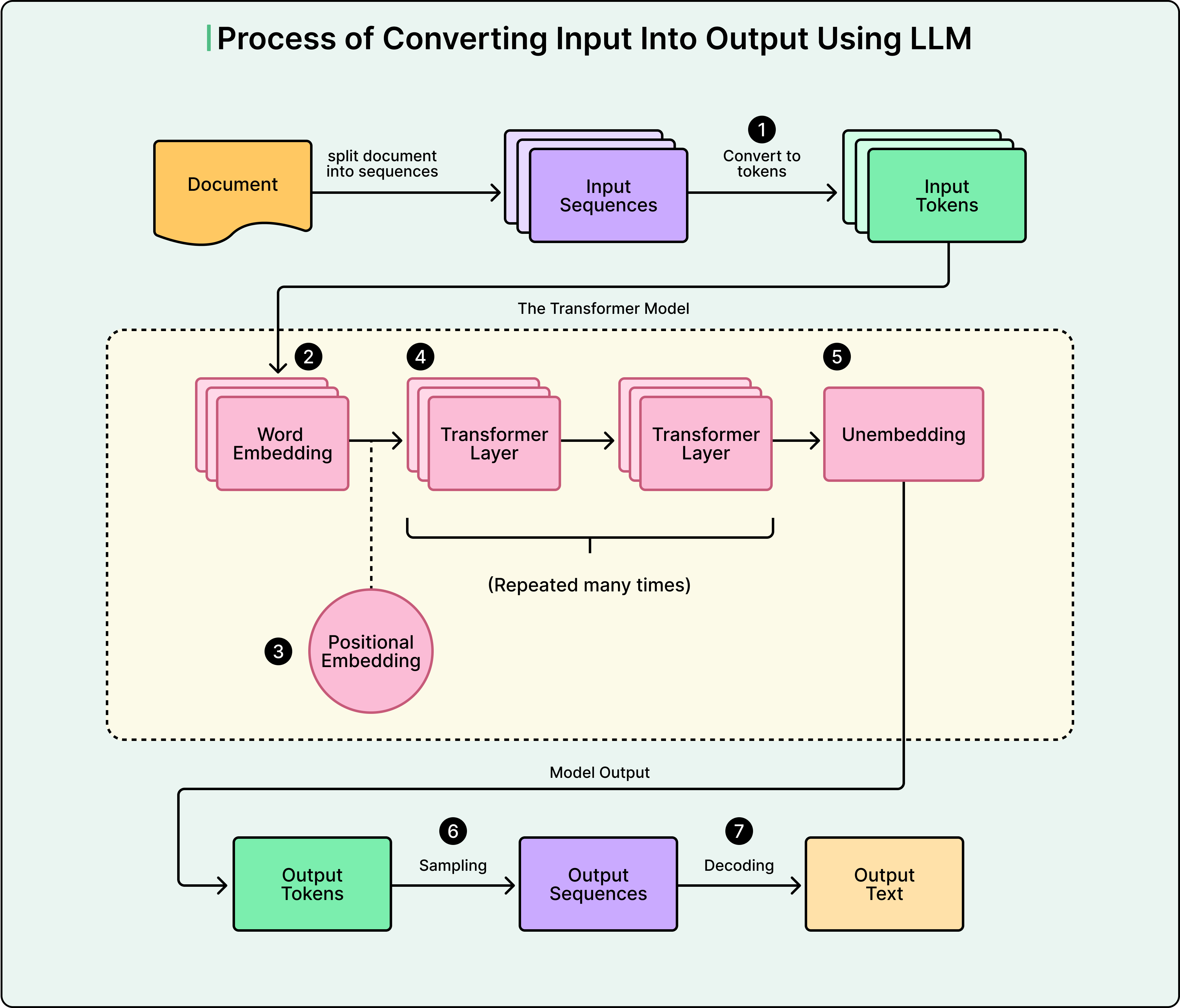
Step 1: From Text to Tokens
Before any computation can happen, the model must convert text into a form it can work with. This begins with tokenization, where text gets broken down into fundamental units called tokens. These are not always complete words. They can be subwords, word fragments, or even individual characters.
Consider this example input: “I love transformers!” The tokenizer might break this into: [”I”, “ love”, “ transform”, “ers”, “!”]. Notice that “transformers” became two separate tokens. Each unique token in the vocabulary gets assigned a unique integer ID:
“I” might be token 150
“love” might be token 8942
“transform” might be token 3301
“ers” might be token 1847
“!” might be token 254
These IDs are arbitrary identifiers with no inherent relationships. Tokens 150 and 151 are not similar just because their numbers are close. The overall vocabulary typically contains 50,000 to 100,000 unique
...This excerpt is provided for preview purposes. Full article content is available on the original publication.