Google Gemini 3 Is the Best Model Ever. One Score Stands Out Above the Rest
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Goodhart's law
17 min read
Linked in the article (7 min read)
-
Mixture of experts
12 min read
The article mentions Gemini 3 uses 'sparse mixture-of-experts (the industry standard)' architecture. Understanding this machine learning technique would help readers grasp why this architecture choice matters for AI model performance and efficiency.
-
Fluid and crystallized intelligence
12 min read
The article explicitly references François Chollet's use of 'fluid intelligence rather than crystallized intelligence' to explain why ARC-AGI is uniquely challenging for AI models. This psychological concept from Raymond Cattell helps readers understand the fundamental distinction the benchmark is measuring.

Google has released Gemini 3, the most-awaited model since GPT-5 (the launch includes the Pro version and Deep Think, the reasoning version). Gemini 3 is great, much better than the alternatives—including GPT-5.1 (recently released by OpenAI) and Claude Sonnet 4.5 (from Anthropic)—but I wouldn’t update much on benchmark scores (they’re mostly noise!). However, there’s one achievement that stands out to me as not only impressive but genuinely surprising.
But before I go into that, let’s do a quick review of just how good Gemini 3 is compared to the competition. Google says Gemini 3 has “state-of-the-art reasoning capabilities, world-leading multimodal understanding, and enables new agentic coding experiences,” but when every new model from a frontier AI company is accompanied by the same kind of description, I believe the differences are better understood with images (and, of course, firsthand experience with the models).
Google tested Gemini 3 Pro against Gemini 2.5 Pro, Claude Sonnet 4.5, and GPT-5.1 (the best models) on 20 benchmarks. It got the top score in 19 of them. Google’s new model dominates in 95% of the tests companies use to measure AI’s skill. Crazy:

Look at that bolding. Some notable mentions:
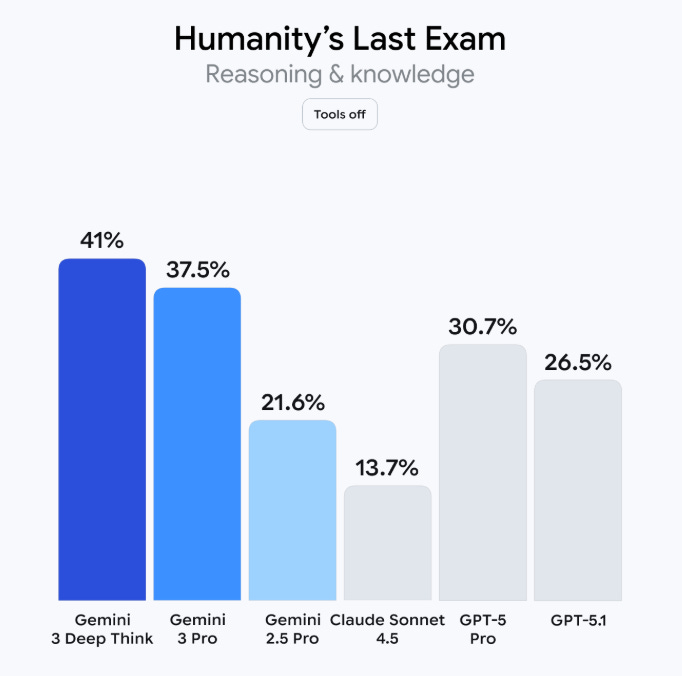
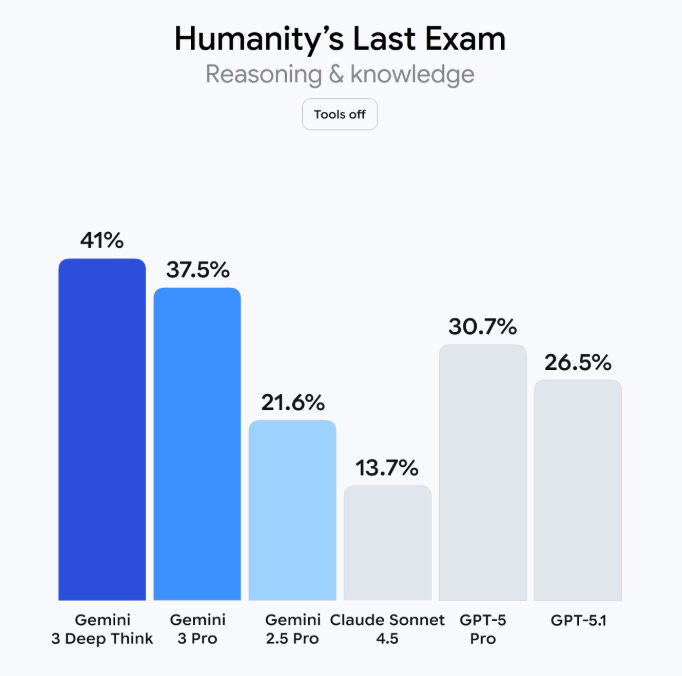
Gemini 3 Pro achieved an 11 percentage-point jump on Humanity’s Last Exam (a benchmark consisting of “2,500 challenging questions across over a hundred subjects”), up to 37.5% from GPT-5.1’s 26.5%.
Source: Google Gemini 3 Pro earned ~$5.5k on Vending-Bench 2, the vending machine benchmark (it tries to answer a valuable real-world question: Can AI models run a profitable business across long horizons?), compared to ~$3.8k from Sonnet 4.5.
Source: Google There’s a ~40% gap between Gemini 3 Pro and the competition in SimpleQA Verified, a factuality benchmark that measures how well AI models answer simple fact-checking questions (important for hallucinations).

Source: Google DeepMind Gemini 3 Pro got first place in the Artificial Analysis Intelligence Index (comprising 10 different evaluations; it came first in five), three points above the second-best model, OpenAI’s GPT-5.1: it’s the largest gap in a long time.

Source: Artificial Analysis



I usually dislike benchmarks as a measure of quality or reliability, or intelligence—my stance on the topic can be summarized by this: “how well AI does on a test measures how well AI does on a test”—but it’s hard to deny that whatever it is that these
...This excerpt is provided for preview purposes. Full article content is available on the original publication.