Giving your AI a Job Interview
Deep Dives
Explore related topics with these Wikipedia articles, rewritten for enjoyable reading:
-
Goodhart's law
17 min read
The article discusses how AI benchmarks become problematic when models are optimized specifically for them - a direct application of Goodhart's law ('when a measure becomes a target, it ceases to be a good measure'). This concept provides deeper theoretical grounding for the benchmark gaming issues described.
-
Psychometrics
14 min read
The article grapples with fundamental measurement challenges - uncalibrated tests, unknown validity, and what scores actually measure. Psychometrics is the scientific discipline that addresses exactly these problems for measuring human abilities, and the same principles apply to AI evaluation.
-
g factor (psychometrics)
15 min read
The article explicitly references an 'underlying ability factor' that different benchmarks seem to measure collectively. This directly parallels the g factor theory in intelligence research - the idea that diverse cognitive tests correlate because they tap into a general intelligence factor.
Given how much energy, literal and figurative, goes into developing new AIs, we have a surprisingly hard time measuring how “smart” they are, exactly. The most common approach is to treat AI like a human, by giving it tests and reporting how many answers it gets right. There are dozens of such tests, called benchmarks, and they are the primary way of measuring how good AIs get over time.
There are some problems with this approach.
First, many benchmarks and their answer keys are public, so some AIs end up incorporating them into their basic training, whether by accident or so they can score highly on these benchmarks. But even when that doesn’t happen, it turns out that we often don’t know what these tests really measure. For example, the very popular MMLU-Pro benchmark includes questions like “What is the approximate mean cranial capacity of Homo erectus?” and “What place is named in the title of the 1979 live album by rock legends Cheap Trick?” with ten possible answers for each. What does getting this right tell us? I have no idea. And that is leaving aside the fact that tests are often uncalibrated, meaning we don’t know if moving from 84% correct to 85% is as challenging as moving from 40% to 41% correct. And, on top of all that, for many tests, the actual top score may be unachievable because there are many errors in the test questions and measures are often reported in unusual ways.
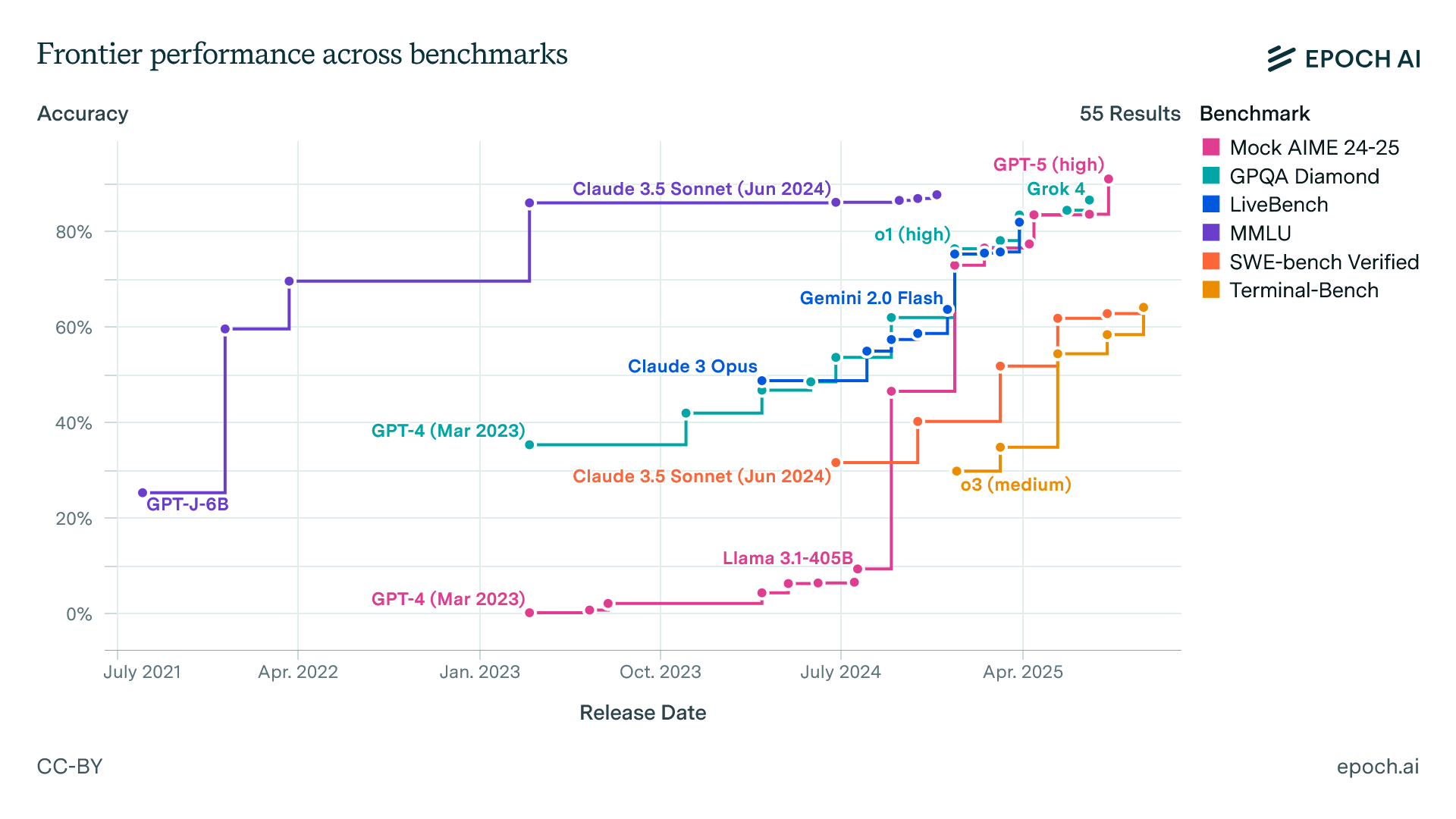
Despite these issues, all of these benchmarks, taken together, appear to measure some underlying ability factor. And higher-quality benchmarks like ARC-AGI and METR Long Tasks show the same upward, even exponential, trend. This matches tests of the real-world impact of AI across industries that suggest that this underlying increase in “smarts” translates to actual ability in everything from medicine to finance.
So, collectively, benchmarking has real value, but the few robust individual benchmarks focus on math, science, reasoning, and coding. If you want to measure writing ability or sociological analysis or business advice or empathy, you have very
...This excerpt is provided for preview purposes. Full article content is available on the original publication.