The State of Reinforcement Learning for LLM Reasoning
A lot has happened this month, especially with the releases of new flagship models like GPT-4.5 and Llama 4. But you might have noticed that reactions to these releases were relatively muted. Why? One reason could be that GPT-4.5 and Llama 4 remain conventional models, which means they were trained without explicit reinforcement learning for reasoning.
Meanwhile, competitors such as xAI and Anthropic have added more reasoning capabilities and features into their models. For instance, both the xAI Grok and Anthropic Claude interfaces now include a "thinking" (or "extended thinking") button for certain models that explicitly toggles reasoning capabilities.
In any case, the muted response to GPT-4.5 and Llama 4 (non-reasoning) models suggests we are approaching the limits of what scaling model size and data alone can achieve.
However, OpenAI's recent release of the o3 reasoning model demonstrates there is still considerable room for improvement when investing compute strategically, specifically via reinforcement learning methods tailored for reasoning tasks. (According to OpenAI staff during the recent livestream, o3 used 10× more training compute compared to o1.)
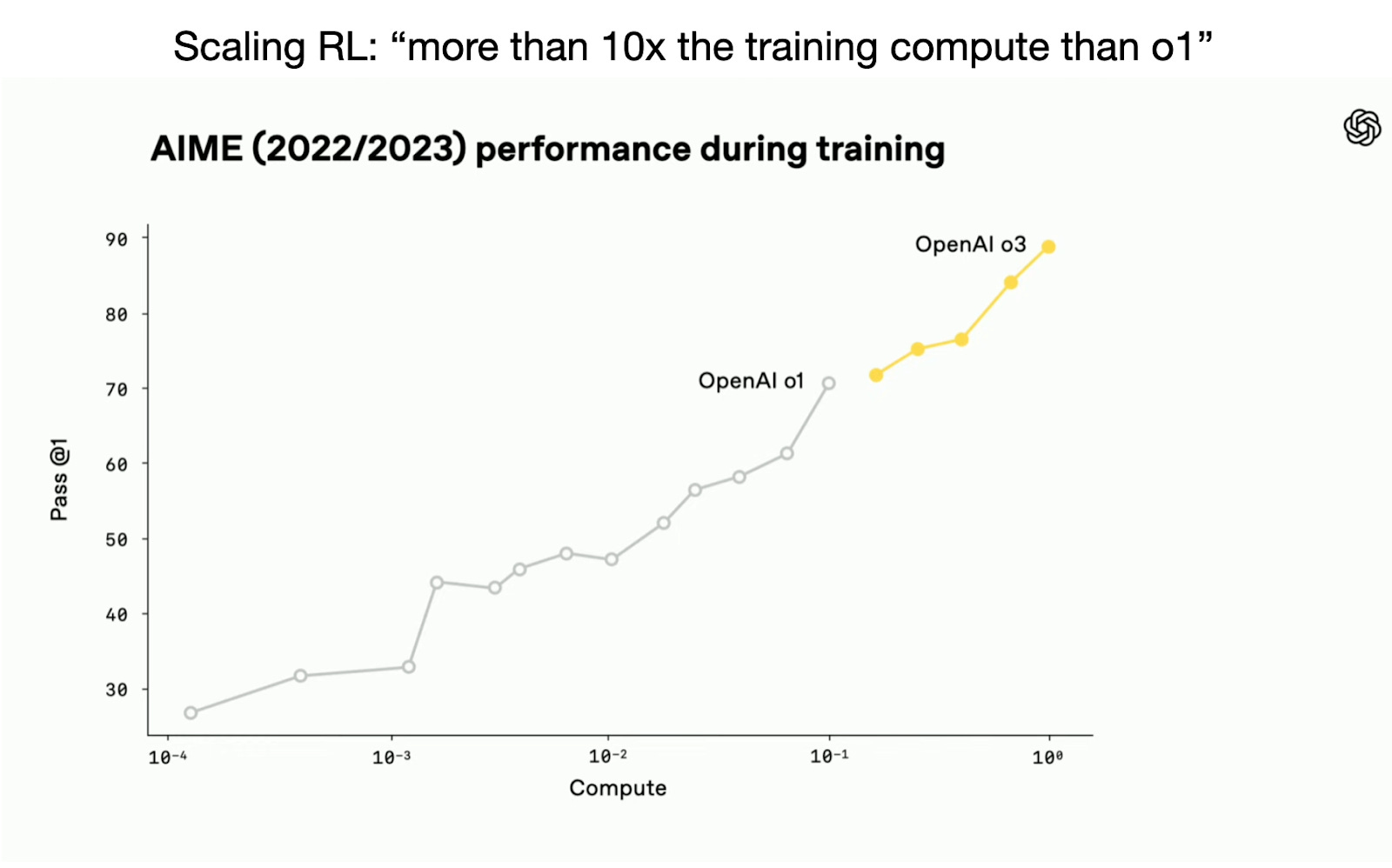
While reasoning alone isn't a silver bullet, it reliably improves model accuracy and problem-solving capabilities on challenging tasks (so far). And I expect reasoning-focused post-training to become standard practice in future LLM pipelines.
So, in this article, let's explore the latest developments in reasoning via reinforcement learning.

Because it is a relatively long article, I am providing a Table of Contents overview below. To navigate the table of contents, please use the slider on the left-hand side in the web view.
Understanding reasoning models
RLHF basics: where it all started
A brief introduction to PPO: RL's workhorse algorithm
RL algorithms: from PPO to GRPO
RL reward modeling: from RLHF to RLVR
How the DeepSeek-R1 reasoning models were trained
Lessons from recent RL papers on training reasoning models
Noteworthy research papers on training reasoning models
Tip: If you are already familiar with reasoning basics, RL, PPO, and GRPO, please feel free to directly jump ahead to the “Lessons from recent RL papers on training reasoning models” section, which contains summaries of interesting insights from recent reasoning research papers.
Understanding reasoning models
The big elephant in the room is, of course, the definition of reasoning. In short, reasoning is about inference and training techniques
...This excerpt is provided for preview purposes. Full article content is available on the original publication.