Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)
How do we actually evaluate LLMs?
It’s a simple question, but one that tends to open up a much bigger discussion.
When advising or collaborating on projects, one of the things I get asked most often is how to choose between different models and how to make sense of the evaluation results out there. (And, of course, how to measure progress when fine-tuning or developing our own.)
Since this comes up so often, I thought it might be helpful to share a short overview of the main evaluation methods people use to compare LLMs. Of course, LLM evaluation is a very big topic that can’t be exhaustively covered in a single resource, but I think that having a clear mental map of these main approaches makes it much easier to interpret benchmarks, leaderboards, and papers.
I originally planned to include these evaluation techniques in my upcoming book, Build a Reasoning Model (From Scratch), but they ended up being a bit outside the main scope. (The book itself focuses more on verifier-based evaluation.) So I figured that sharing this as a longer article with from-scratch code examples would be nice.
In Build A Reasoning Model (From Scratch), I am taking a hands-on approach to building a reasoning LLM from scratch.
If you liked “Build A Large Language Model (From Scratch)”, this book is written in a similar style in terms of building everything from scratch in pure PyTorch.
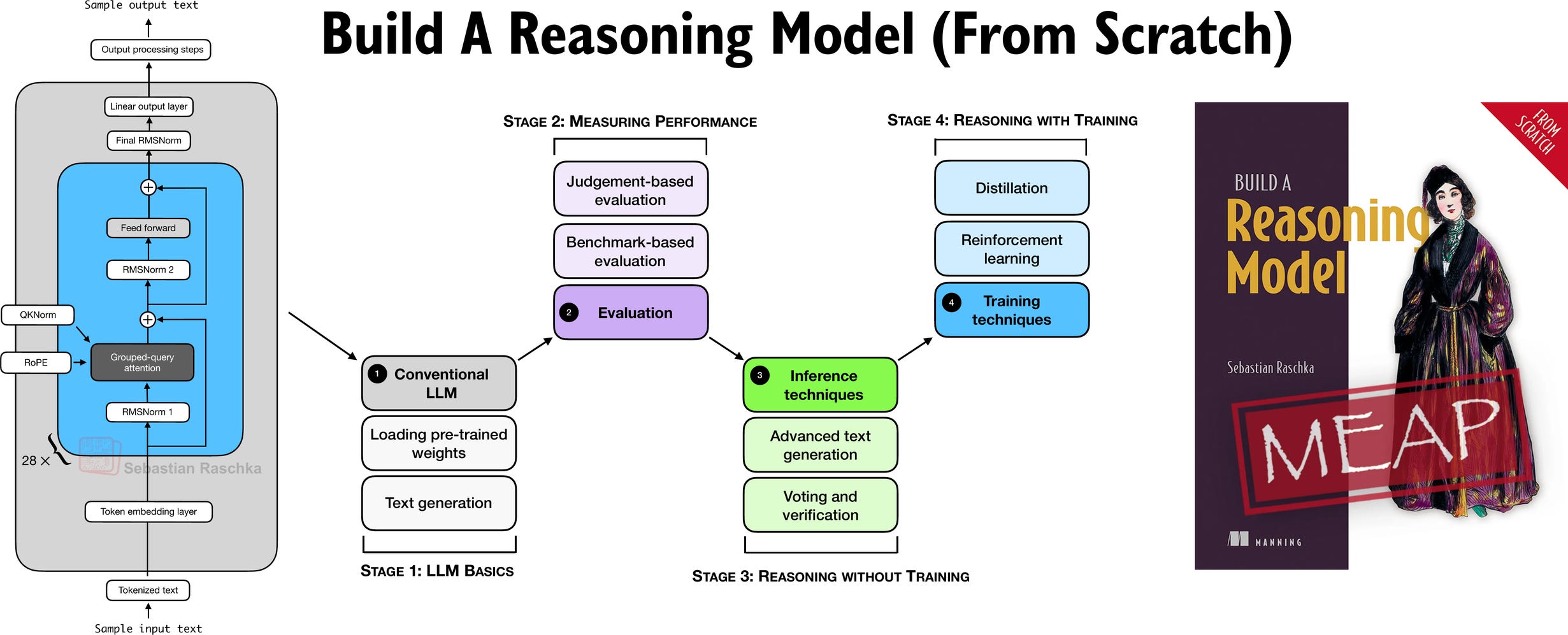
The book is currently in early-access with >100 pages already online, and I have just finished another 30 pages that are currently being added by the layout team. If you joined the early access program (a big thank you for your support!), you should receive an email when those go live.
PS: There’s a lot happening on the LLM research front right now. I’m still catching up on my growing list of bookmarked papers and plan to highlight some of the most interesting ones in the next article.
But now, let’s discuss the four main LLM evaluation methods along with their from-scratch code implementations to better understand
...This excerpt is provided for preview purposes. Full article content is available on the original publication.