The Claude Code Experiment: Building Cliodynamics with AI Pair Programming
Introduction: An Experiment in AI-Assisted Development
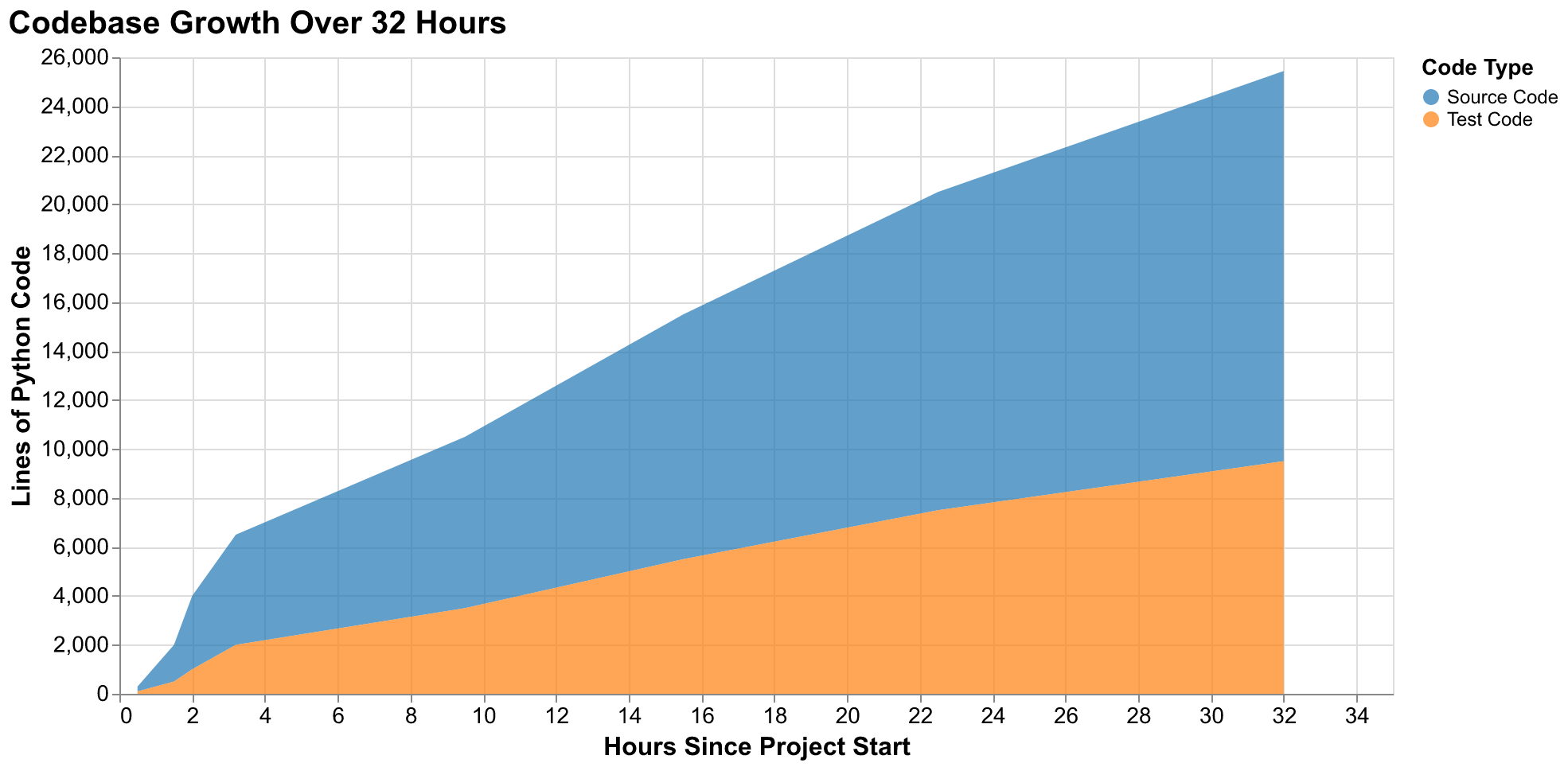
This essay documents an experiment in software development methodology. Over thirty-two hours spanning two days in January 2026, we built a complete cliodynamics research platform from scratch using Claude Code, Anthropic's AI-powered development environment running the Opus 4.5 model. The project produced 15,939 lines of source code, 9,502 lines of tests, eight long-form essays totaling over 96,000 words, an interactive web explorer that runs entirely in the browser, and over 100 visual assets including charts, illustrations, and animations. This essay tells the story of how that happened, what worked, what did not work, and what it suggests about the future of software development.
The experiment began with a question that has occupied many software developers' minds since the advent of large language models capable of generating coherent code: can AI pair programming actually work for substantial projects? Not toy examples that fit in a single file, not simple scripts that demonstrate capability without practical value, but real software with complex interdependencies, careful architectural decisions, comprehensive test coverage, and production-quality outputs that actual users might find valuable. We set out to answer this question empirically by attempting something ambitious: replicating Peter Turchin's cliodynamics research in a complete, documented, and publicly accessible form that anyone could understand and extend.
The choice of cliodynamics as our test domain was deliberate and strategic. This field requires mathematical modeling with systems of coupled differential equations describing population dynamics, elite competition, and political stress accumulation. It requires data integration from historical databases spanning thousands of years and dozens of civilizations. It requires parameter calibration using global optimization algorithms that search high-dimensional parameter spaces for optimal fits. It demands sophisticated visualization that can represent time series, phase space trajectories, and cyclical patterns. And it requires clear explanatory writing that makes complex mathematical and historical concepts accessible to readers without specialized training. This scope spans the full stack from numerical computation to web presentation. If AI pair programming could handle this breadth and depth successfully, it could plausibly handle most software projects that developers face. If it could not, we would learn concretely where the boundaries of current capability lie.
The results of this experiment surprised us in both directions. The productivity gains exceeded our most optimistic projections, with work that would have taken weeks or months of traditional development compressing into roughly thirty-two hours of active engagement. The code quality matched or exceeded what we would expect from careful solo development, with comprehensive type hints, thorough documentation, and consistent patterns throughout the codebase. The documentation was not merely adequate but genuinely educational, with essays that we believe readers will find valuable independent of the code they describe. But the path to these results was far from straightforward. We encountered failures, rework, and frustrations that revealed fundamental limitations in current AI systems. This essay aims to provide an honest accounting of both the successes and the struggles, offering practical lessons for developers considering similar approaches.
We will structure this account around several key themes. First, we present the concrete facts: the timeline of development activity, the metrics extracted from our session logs, and the architecture we employed to coordinate human and AI contributions. Then we explore the collaboration model that emerged through practice, examining how the division of labor between humans and AI systems evolved as we gained experience. We dive deep into the technical challenges of context windows and session management, which proved to be the most significant constraints on effective development. We analyze the role of GitHub as our coordination hub, enabling parallel work that would otherwise have been impossible. Finally, we assess the experiment with intellectual honesty, discussing both what worked remarkably well and what failed despite our best efforts. Throughout, we ground our observations in specific data from the project, not speculation about what might happen in hypothetical scenarios.
The Timeline: Thirty-Two Hours from Zero to Production
The project began at precisely 10:34 AM Central Time on January 22, 2026, with a single commit creating the initial project documentation. The first file committed was TURCHIN.md, a markdown document summarizing Peter Turchin's research program, the key concepts of cliodynamics and Structural-Demographic Theory, and the specific goals our project would pursue. This document would serve as persistent context for all subsequent work, anchoring the project's purpose in the codebase itself where any Claude Code session could reference it.
What followed this initial commit was an intensive but carefully structured development process that produced results we genuinely could not have imagined achieving through traditional methods in the same timeframe. The compression of elapsed time was remarkable in itself, but equally remarkable was the consistency of output quality maintained throughout this sprint. There was no degradation in code quality or documentation thoroughness as fatigue set in, because the AI did not experience fatigue. The human contribution remained focused on direction and verification while the AI handled the implementation details that typically exhaust human attention over long coding sessions.
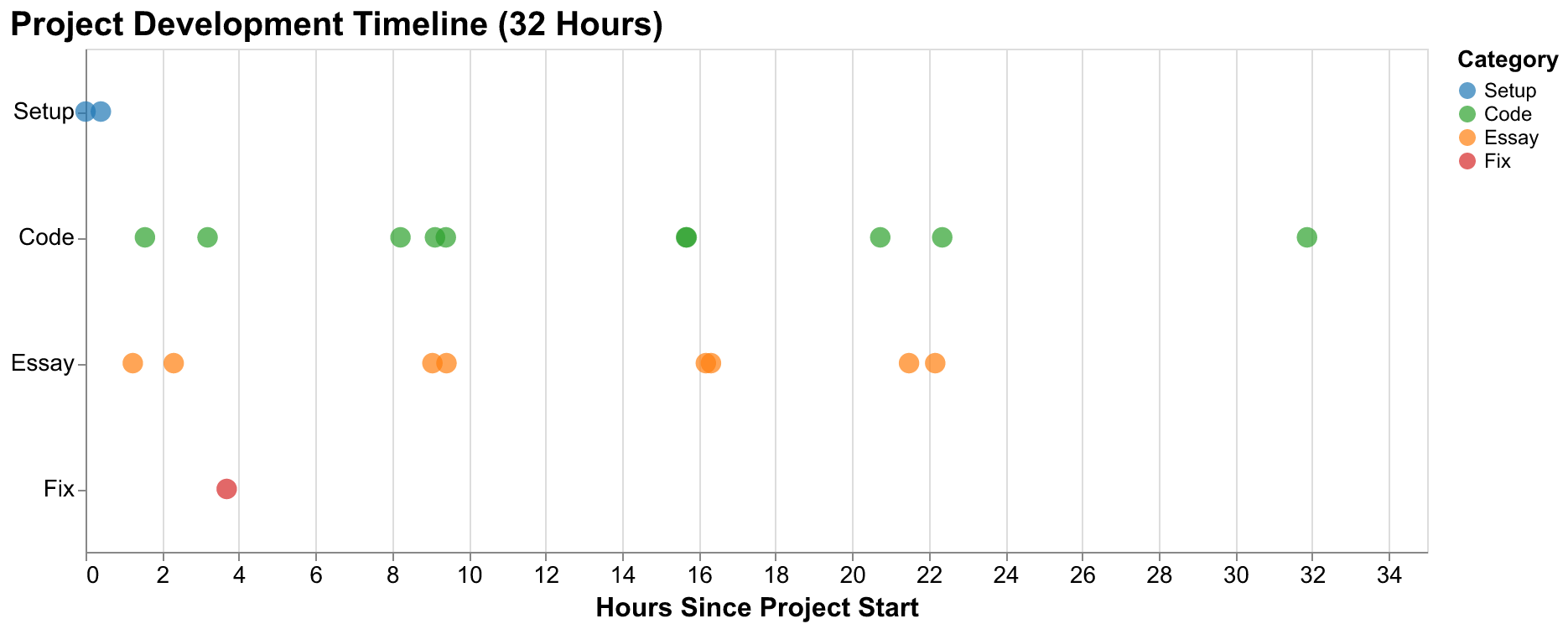
The first hour established the project's foundation. By 10:43 AM, nine minutes after the initial commit, GitHub Actions workflows for continuous integration were in place. These included the Claude PR Assistant for automated code review on every pull request and standard CI checks for code formatting and test execution. By 10:50 AM, the worker framework was fully documented in CLAUDE.md (instructions for AI sessions) and MANAGER_ROLE.md (procedures for the orchestrating session). By 10:58 AM, complete project scaffolding was merged, including the directory structure mirroring our planned architecture, dependency management via pyproject.toml with all anticipated dependencies specified, pytest configuration for testing, and initial module stubs. This speed of foundation-laying reflects one of AI programming's most transformative strengths: boilerplate generation that would normally require hours of consulting documentation, copying templates from previous projects, and carefully configuring tooling happened in minutes without tedium or errors.
Between 11:00 AM and noon, the core Structural-Demographic Theory implementation took shape. Multiple workers operated in parallel on complementary components. One worker built the data access layer for querying historical records, establishing the SeshatDB class that provides a clean interface over the complex underlying CSV data. Another worker implemented the mathematical equations describing population dynamics, elite competition, wage depression, state fiscal strain, and political stress accumulation. A third worker integrated SciPy's ODE solvers with our model equations, creating the simulation runner that would become the computational engine of the entire system. Each of these components would typically require careful implementation with thorough testing. The SDT equations alone involve five coupled differential equations with more than a dozen parameters. Yet the implementation was complete with comprehensive unit tests covering normal cases, edge cases, and error conditions in under two hours elapsed time.
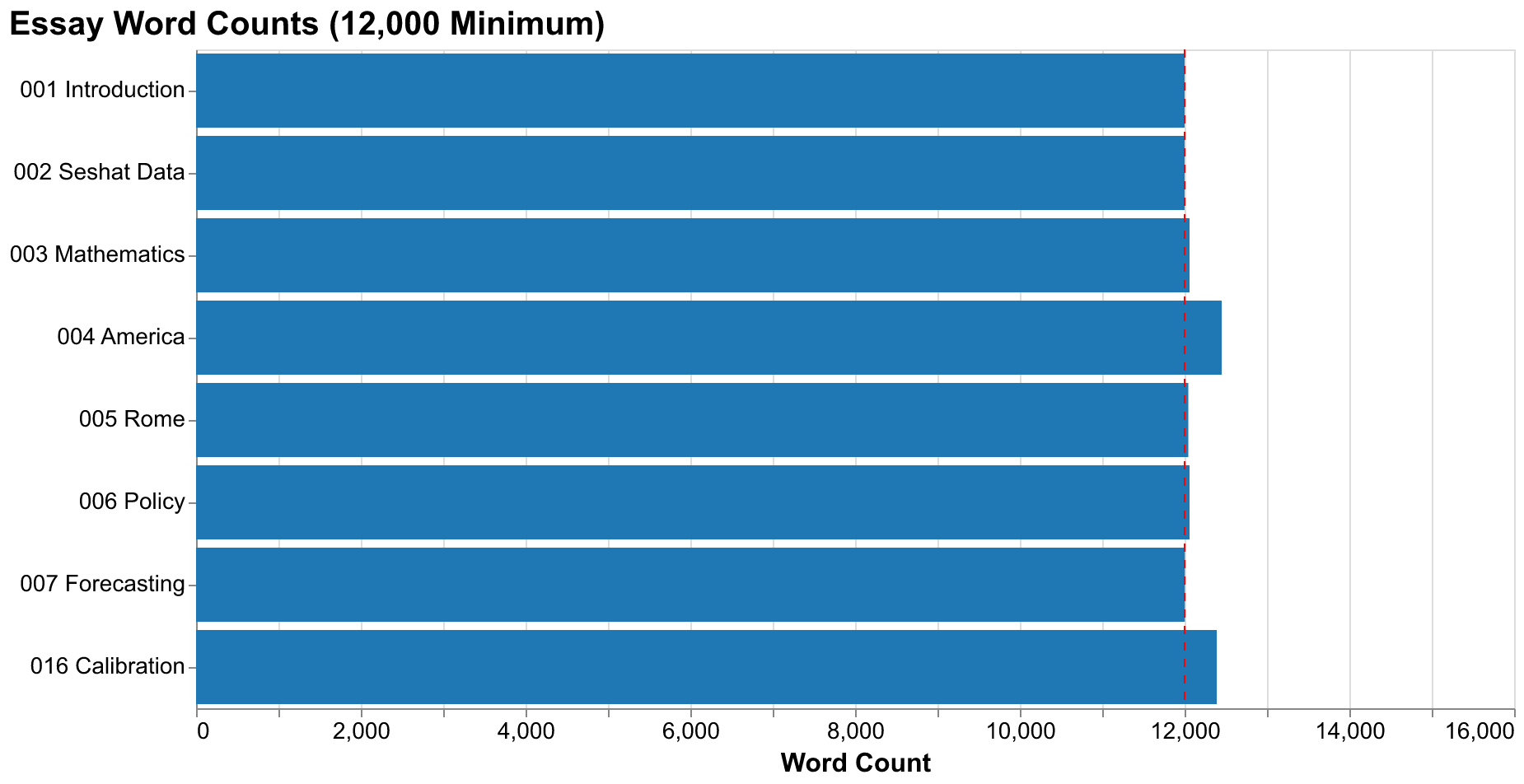
Our first essay, introducing the project and explaining cliodynamics from first principles to readers without prior background, was published to GitHub Pages at 11:48 AM. This was less than ninety minutes after the project's creation. The essay was not a placeholder or stub waiting to be filled in later. It was a complete 12,000-word document explaining Structural-Demographic Theory conceptually, introducing Peter Turchin's research program and its predictions, and describing our project's goals and methodology. The essay included multiple illustrations generated by Google's Gemini image generation API and charts produced with our visualization infrastructure. The speed of this essay production, combined with its quality, was one of the project's most surprising capabilities and reshaped our understanding of what AI could contribute to technical communication.
The afternoon of day one brought calibration frameworks, visualization modules, and our second essay documenting the Seshat Global History Databank. The calibration framework implemented differential evolution and basin-hopping algorithms for parameter optimization, wrapping SciPy's global optimizers with interfaces suited to our specific problem structure. The visualization module established consistent chart styling that would propagate across the entire project, using Altair for declarative specification and Vega-Lite for rendering. The Seshat essay explored the Global History Databank in exhaustive detail, analyzing its data quality characteristics, geographic and temporal coverage patterns, variable completeness rates, and what the data reveals about patterns in social complexity across human history. This essay alone would have represented weeks of research and writing through traditional methods.
By evening, the project had achieved substantial functionality. We had integrated the Seshat API client for live data access beyond the static Equinox-2020 release, downloaded and parsed the Polaris-2025 dataset representing the most current Seshat data available, and produced case studies for both the Roman Empire and the United States. These case studies were not simple demonstrations but serious analyses: reconstructing historical time series from fragmentary evidence, calibrating model parameters to fit historical data using our optimization framework, running simulations forward and backward in time, and analyzing how well the model captured known historical dynamics. The essay on mathematical foundations was published at 7:59 PM, completing day one with four published essays and a fully functional modeling framework capable of serious research applications.
Day two began with animation modules and forecasting pipelines. The animation module, built initially with Matplotlib and later migrated to Plotly for better interactivity, provided animated visualizations of secular cycles evolving over time, phase space trajectories showing how societies move through state space, and model comparisons displaying multiple simulation runs simultaneously. The forecasting pipeline implemented ensemble methods for probabilistic predictions, running many simulations with varied parameters to capture uncertainty, and providing confidence intervals on future trajectories rather than single point predictions. By mid-morning of day two, we had published essays on Rome, America, and parameter calibration, bringing our essay count to seven.
The afternoon of day two saw intensive work on the most ambitious feature: the interactive explorer. This single-page application allows users to adjust model parameters through intuitive slider controls and watch simulations unfold in real-time with animated 2D and 3D visualizations. The explorer runs entirely in the browser using Pyodide (Python compiled to WebAssembly), requiring no backend server. Building this feature required coordinated work across Python simulation code that runs in the browser, JavaScript for the UI framework and event handling, CSS for visual styling and responsive layout, and HTML structure to tie everything together. The entire explorer came together in a single extended session, demonstrating Claude Code's ability to work fluently across the full stack without the context-switching overhead that would slow a human developer moving between such different technologies.
Migration to the Altair visualization library addressed problems with our initial Matplotlib-based charts that had emerged in production. Matplotlib charts exported at wildly varying dimensions, some unreasonably large, and required manual adjustment for each output. Altair provided declarative specification that made consistency easier to maintain. The migration touched dozens of files throughout the codebase but proceeded smoothly thanks to clear patterns established in early modules. Policy simulation frameworks enabled counterfactual analysis, asking questions like "what if the Roman Empire had implemented grain subsidies earlier?" The final push before this essay added Plotly animations for richer interactive visualizations embedded directly in essays and brought the project to its current production state.
The growth curve observed in this project tells a story that likely applies beyond our specific circumstances. Initial infrastructure work proceeds slowly because foundational decisions require careful thought. Every choice at this stage constrains future options, so these decisions merit deliberation even with AI assistance that can implement decisions quickly once made. Then acceleration begins as patterns emerge and can be reused. Once the first visualization module exists, subsequent modules follow its patterns. Once the first case study is complete, the second case study has a template. The middle phase of the project shows explosive growth as established patterns are applied to new features by parallel workers who do not need to rediscover approaches. Finally, velocity decreases in the late phase as focus shifts to polish, integration across components, and handling edge cases that defy pattern application because they are inherently unique. This S-curve of development velocity may characterize AI-assisted projects generally.
Architecture: The Manager-Worker Model
The key architectural innovation that enabled the velocity we observed was our manager-worker model of AI session orchestration. Rather than conducting a single linear conversation with Claude Code where accumulated context would eventually degrade performance, we employed an orchestration pattern where a persistent manager session coordinates multiple independent worker sessions, each focused on a specific bounded task. This architecture emerged from necessity when we hit context limitations, but it proved to be a powerful pattern for AI-assisted development that we would recommend to others attempting similar projects.
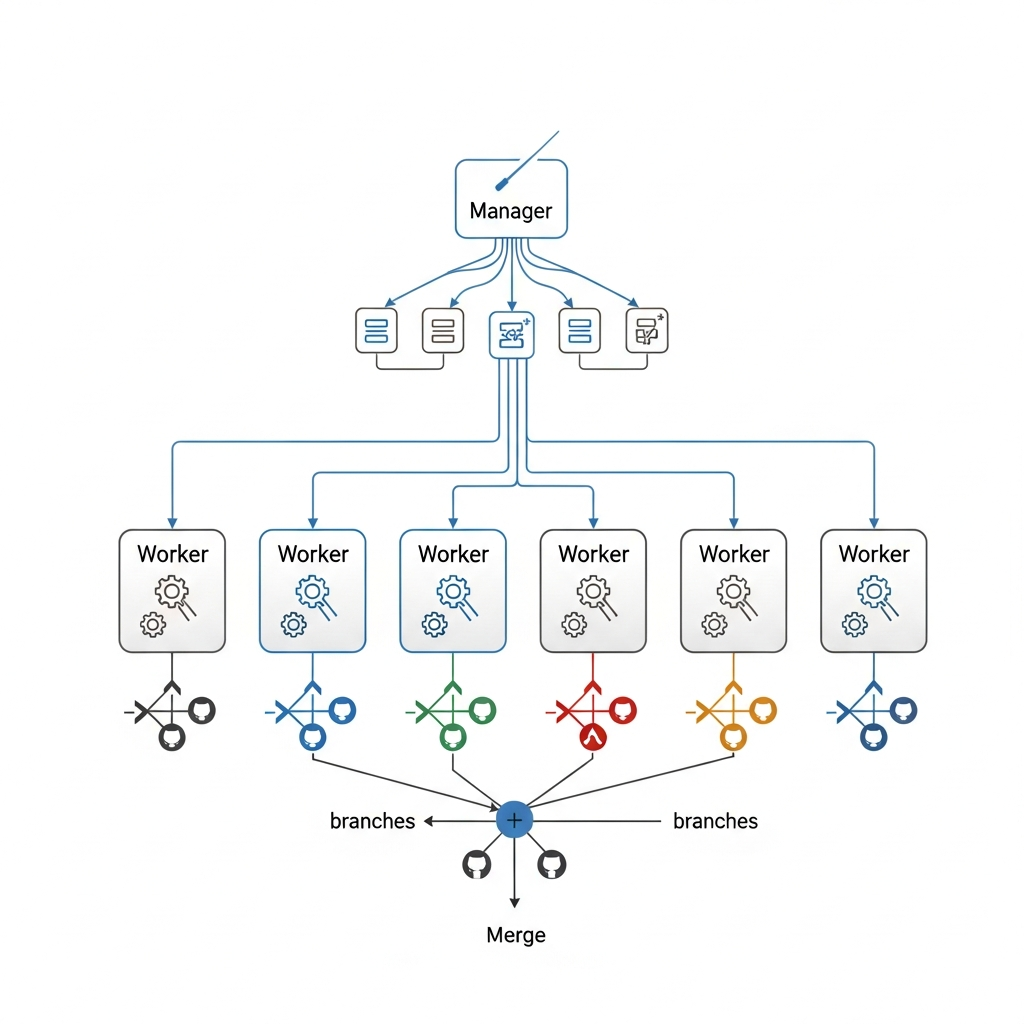
The manager session maintains awareness of the entire project's state and coordinates all development activity. Its responsibilities include tracking all GitHub issues and understanding their dependency relationships, monitoring the current state of the codebase including pending changes in open pull requests, observing the progress of active workers and estimating their expected completion times, and keeping the broader goals of the project in mind when making tactical decisions. Critically, the manager does not implement features directly. Doing so would quickly exhaust its context window with implementation details that matter for specific features but not for overall coordination. Instead, the manager creates GitHub issues with detailed requirements and explicit acceptance criteria, spawns workers to implement those issues in isolated branches, monitors worker progress through the GitHub PR status API, reviews completed pull requests for alignment with architectural vision, and coordinates merges to prevent conflicts between concurrent changes.
Workers are intentionally single-purpose sessions with limited scope. Each worker receives a specific issue number to implement, creates a feature branch from the current state of main, writes the code and tests required to satisfy the issue's explicit acceptance criteria, opens a pull request that references the issue with GitHub's "Closes #N" syntax for automatic issue closure, and terminates upon completion without attempting further work. Workers do not need to understand the full project context, which would be infeasible given context limits. They only need to understand their specific task in sufficient detail and how it connects to the existing codebase through defined interfaces. This scope limitation is actually a feature rather than a constraint to work around: it prevents workers from making unauthorized changes to code outside their remit, keeps each unit of work focused enough to review thoroughly, and ensures that the manager maintains meaningful control over project direction rather than having workers accumulate decision authority.
The manager-worker pattern emerged from direct experience with context window limitations. Claude Code sessions have finite capacity for information, and complex projects quickly exceed what any single session can hold in working memory without degradation. Early in the project, we attempted to implement multiple features in sequence within a single session. Performance visibly degraded as the session accumulated context: responses slowed, earlier decisions were forgotten and contradicted, and code quality declined from the standards established at the start. The solution was decomposing work into independent units that could be implemented in fresh sessions, coordinating through GitHub's durable issue and pull request system rather than through ephemeral conversation context. This transformation turned a limitation into an advantage by enabling parallelism that a single session could never achieve regardless of context capacity.
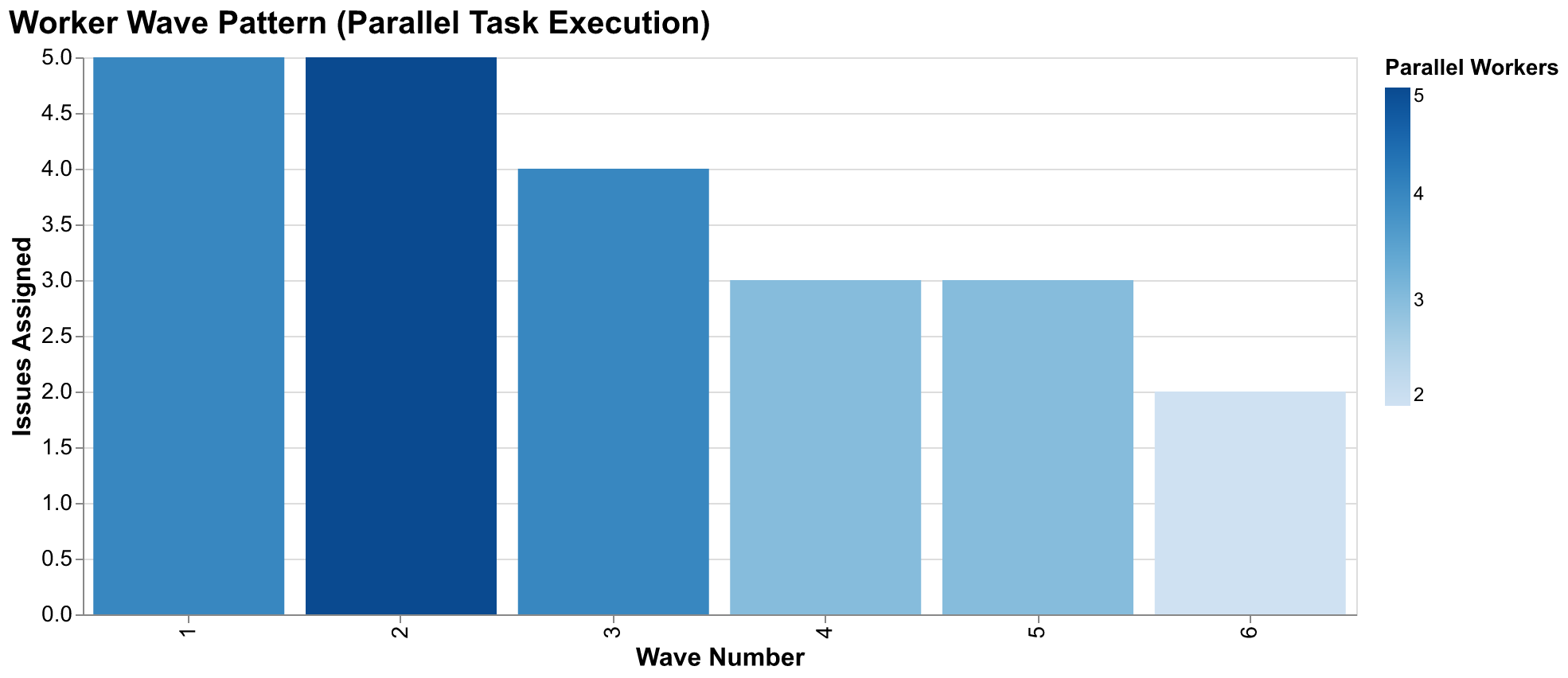
We organized workers into waves based on dependency analysis of the issue graph. The first wave addressed foundational work with no dependencies on other project work: fixing images from previous sessions that had errors, writing initial essays that could stand alone, and building API integration for data access that other features would need. Once those PRs merged and their changes became available on the main branch, we spawned the second wave for dependent features: dataset downloads that required the API client, case studies that required the data layer and simulation engine, and visualization modules that required working simulations to visualize. This dependency-driven wave structure continued through six distinct waves over the project's duration, with parallelism at each wave determined by how many independent tasks were available. At peak parallelism, we had five workers running simultaneously on different aspects of the project, each isolated in its own git branch and Claude Code session context, coordinated only through GitHub's issue tracking and the manager's oversight.
The worker model required explicit documentation of project conventions that workers could learn without conversation history. Workers start fresh without any memory of previous project discussions, so they need to learn standards from the codebase and documentation itself. The CLAUDE.md file evolved to include increasingly detailed conventions as we learned what workers needed to know: code style preferences beyond what linting would catch, testing requirements including coverage expectations and edge cases to consider, documentation standards for docstrings and comments, visualization guidelines for consistency across outputs, and lessons learned from previous failures that new workers should avoid repeating. Workers read this file early in their execution flow and internalize its instructions as constraints on their behavior. When we learned something important about how the project should work through experience with a specific case, we added it to CLAUDE.md rather than relying on any AI session to remember it from a conversation that might not persist.
The Human Role: Direction, Verification, and Intervention
The human's role in this collaboration differed fundamentally from what traditional pair programming might suggest. We did not type code while Claude watched to learn our style, nor did Claude type while we observed and occasionally offered suggestions for improvement. Instead, we operated consistently at a higher level of abstraction than implementation: setting strategic direction at the project level, verifying outputs at the quality assurance level, and intervening tactically when things went demonstrably wrong. This division of labor emerged through practice and proved stable and productive once established.
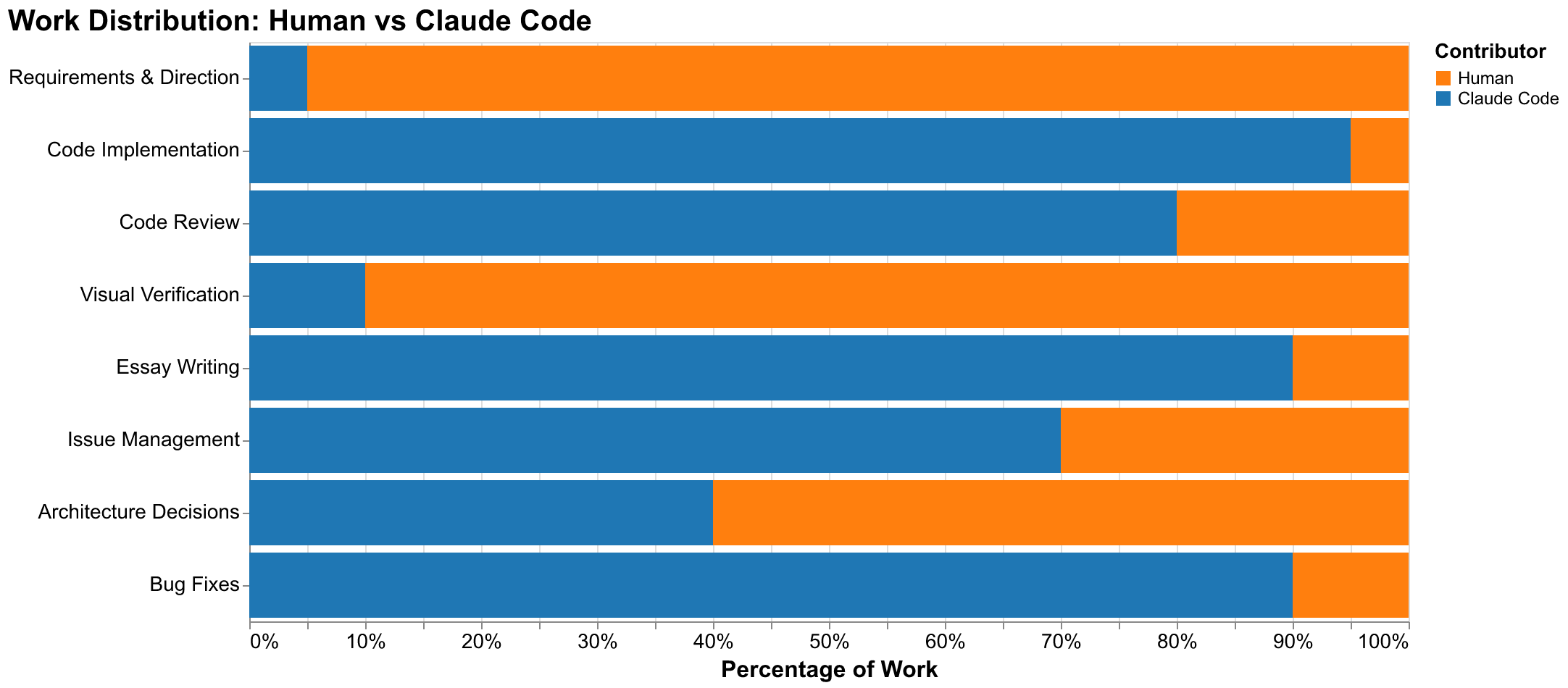
Requirements definition remained almost entirely a human activity throughout the project. We decided what the project should accomplish at the highest strategic level: replicating Turchin's cliodynamics research in an accessible form that could serve both as educational material and as a foundation for further research. We decided what specific features the project needed: data integration with Seshat, mathematical modeling of SDT dynamics, case studies demonstrating application to historical civilizations, essays explaining concepts to general readers, and visualizations making abstract dynamics concrete and intuitive. We decided how those features should behave in detail: what data formats to support, what level of documentation to provide for each function and module, what quality thresholds to maintain for code coverage and visual outputs. Claude Code contributed to requirements through clarifying questions that revealed ambiguities in our initial specifications and through suggesting considerations we had not thought to include, but the fundamental direction and value judgments came from human expertise about what would be worth building and what quality level would satisfy our goals.
Code implementation flipped the contribution ratio almost entirely. Claude Code wrote approximately 95% of the Python code in this project by volume. The human contribution to implementation was limited to occasional corrections when something was demonstrably wrong and violated explicit requirements, style adjustments when the AI's functional choices differed from aesthetic preferences that we had not thought to specify, and architectural guidance when the AI proposed structures that would not serve long-term maintainability or extensibility goals. This heavy delegation to AI was not because we lacked the ability to write the code ourselves. We could have implemented everything in this project given sufficient time. The delegation was a conscious choice to leverage AI's comparative advantage in implementation speed and consistency, freeing human attention for activities where human judgment was irreplaceable.
Visual verification proved to be a critical human responsibility that we had not fully appreciated before starting this experiment. AI systems can generate images and charts readily, but they cannot reliably evaluate whether those generated outputs are actually correct according to human perception and domain knowledge. The evaluation requires understanding what the output is supposed to represent (which the AI may have) and perceiving whether the representation achieves that goal accurately (which current AI cannot reliably assess from pixels). We encountered numerous examples of this limitation. Maps had labels in wrong geographic locations, with Rome labeled somewhere in the Atlantic Ocean rather than on the Italian peninsula. Charts had distorted proportions that made comparison between values misleading. Animations had visual artifacts or confusing transitions that obscured rather than illuminated the dynamics they depicted. Text generated in images sometimes did not match the prompts, with labels missing or changed in ways that undermined the intended communication. Every visual asset in this project underwent human review before being committed to the repository, and many required regeneration, sometimes multiple times, due to problems that Claude Code could not detect through any means available to it. The CLAUDE.md file now includes explicit warnings about visual verification precisely because we learned through embarrassing early mistakes that this human review step cannot be skipped.
Architecture decisions occupied a middle ground between pure human direction and AI implementation. Claude Code possesses substantial knowledge of software architecture patterns from its training on high-quality codebases and technical literature. It can suggest appropriate patterns for given problem structures: dependency injection for testing flexibility, repository patterns for data access abstraction, strategy patterns for algorithm selection, and dozens of others. But the final decisions about how to structure this specific codebase, which patterns to employ among viable alternatives, and how components should interact through defined interfaces required human judgment about project-specific tradeoffs. Should we prioritize flexibility to handle future requirements we cannot anticipate, or simplicity that makes the current implementation easier to understand and maintain? Should we optimize for performance in computation-heavy simulation code, or maintainability that allows future contributors to modify the code confidently? These tradeoffs have no universal right answers, and resolving them required domain knowledge about our specific goals that no AI could fully possess without our context and intentions.
Intervention was necessary more frequently than we had initially expected given the quality of AI outputs on average. Despite clear instructions in CLAUDE.md and detailed acceptance criteria in issues, workers occasionally misunderstood requirements in ways that satisfied the letter of specifications while violating their spirit. The manager session sometimes lost track of dependency relationships as context accumulated, or spawned conflicting work that would require resolution at merge time. Claude Code occasionally hallucinated features that did not exist in libraries, or proposed approaches that would not work due to constraints not mentioned in documentation. Each of these failure modes required human attention to diagnose the root cause and intervene with corrections. The collaboration was not a fire-and-forget automation where the human could step away and return to completed work. It required sustained engagement with the process, monitoring for problems, and addressing failures as they arose. This ongoing attention was the cost of the productivity benefits.
The AI Role: Implementation, Documentation, and Consistency
Claude Code's contributions to this project were substantial and multifaceted, spanning code implementation, test creation, documentation writing, and cross-technology integration. Understanding specifically what AI systems do well in development contexts helps calibrate expectations appropriately and identifies where AI assistance adds genuine value worth the costs of coordination and oversight.
Code implementation was Claude Code's strongest domain by a significant margin. Given clear requirements with specific acceptance criteria, the system produced working Python code with remarkable consistency across a large codebase developed in parallel by many independent sessions. The code followed modern best practices that a senior developer would endorse and a code reviewer would approve: type hints throughout for static analysis compatibility and IDE support, comprehensive docstrings in Google style for automatic documentation generation, proper error handling with informative messages that would help users diagnose problems, and logical organization within files and across the module structure that grouped related functionality and separated concerns appropriately. The AI adapted to project conventions after seeing just a few examples of the patterns we preferred. It maintained consistency across files created by different worker sessions without explicit coordination or reminders. The 15,939 lines of source code in this project are, with only minor exceptions for manual corrections, AI-generated in their entirety, yet they read as if written by a single careful developer with consistent style and standards rather than a team that might drift in different directions.
Testing proved to be another strong capability that matched implementation quality. Claude Code produced 9,502 lines of test code over the project's duration, maintaining a test-to-source ratio of approximately 60% throughout without explicit enforcement or monitoring. This ratio emerged naturally from the AI following patterns established in early test files that demonstrated our expectations for coverage. The tests were not trivial assertions of obvious conditions that would pass regardless of implementation correctness. They included edge cases that human developers, especially under time pressure, often neglect to consider: empty inputs, boundary values, large datasets that might expose performance issues, and unusual but valid parameter combinations. They included explicit testing of error conditions with verification that appropriate exceptions were raised with useful messages. They included integration scenarios that tested component interactions across module boundaries, not just unit tests of isolated functions. The test suite catches real bugs: several times during development, tests failed on PR branches because new code introduced regressions that affected existing functionality, and these failures prevented bugs from reaching the main branch where they would have been harder to diagnose and fix.
Documentation emerged naturally from Claude Code's extensive training on high-quality codebases and technical writing. The essays in this project, totaling over 96,000 words across eight published documents, were drafted by Claude Code with refinement through human review rather than written from scratch by humans. The AI demonstrated genuine understanding of the technical content being documented, not merely surface-level paraphrasing. It wove narrative threads through data analysis, providing context that helped readers understand why findings mattered. It provided accessible explanations of complex mathematical concepts without sacrificing accuracy. It maintained a consistent voice and tone across multiple long-form pieces written in different sessions, adapting to the style guide in WRITING_STYLE.md. Each essay required some editing for stylistic polish and factual accuracy verification, but the fundamental structure, content, arguments, and even much of the final prose came from AI generation. The ability to produce publication-quality technical writing at this volume and speed was one of the project's most surprising capabilities and significantly expanded our conception of what AI can contribute to software projects beyond code.
Consistency across a large codebase was perhaps the most underrated contribution that AI assistance provided, valuable precisely because it is difficult for humans to maintain without deliberate effort and tooling. Human developers have bad days where focus wavers, moments of distraction from notifications or interruptions, varying energy levels across a long project, and different interpretations of guidelines depending on context and mood at the time of implementation. Code quality fluctuates accordingly, and maintaining consistency across tens of thousands of lines requires either exceptional discipline or external enforcement through code review and automated linting. Claude Code produced the same quality of output regardless of what hour it was, how many features had already been implemented, or how complex the accumulated codebase had become. Whether implementing the first module at project start or the fortieth module days later, the output maintained uniform standards. Variable naming conventions stayed consistent. Error handling patterns were applied uniformly. Documentation styles matched across files. Structural choices followed established precedents. This machine consistency reduced cognitive load during human review, because reviewers could trust that deviations from patterns were meaningful rather than random variation, and it made the codebase easier to navigate for anyone reading it later.
Breadth of capability enabled full-stack development without the context-switching costs that slow human developers working across technologies. This project spans Python for numerical computation and modeling, HTML for document structure, CSS for visual styling and responsive layout, JavaScript for client-side interactivity and real-time updates, Markdown for documentation and issue specifications, YAML for configuration files including GitHub Actions workflows, and JSON for data exchange and structured storage. A human developer working solo across this technology stack would need to context-switch between different syntaxes, recall different idioms appropriate to each language, and mentally shift between different abstraction levels. Claude Code operated fluently across all of these technologies, maintaining appropriate idioms in each context without confusion. The interactive explorer combined Python simulation code running in WebAssembly, JavaScript visualization code using Plotly.js, HTML structure defining the page layout, and CSS styling controlling appearance, all produced in a single coherent implementation by one worker session that understood how these pieces fit together.
Context Windows and Session Management
The single greatest constraint on Claude Code's effectiveness for substantial projects is the context window limitation. Every conversation has a finite capacity for information measured in tokens, roughly corresponding to words and code characters combined. As that capacity fills with previous messages in the conversation history, code snippets shared during discussion, tool outputs returned from command execution, and accumulated conversational state, Claude Code's effective working memory for the current task shrinks. Eventually, earlier parts of the conversation become inaccessible to the model, and the AI begins making decisions without awareness of prior context that informed earlier choices in the same conversation.

We observed context degradation manifesting in several distinct forms during this project. The most obvious and easily detected form was literal forgetting: the AI would ask questions about information clearly provided earlier in the same conversation, or would propose solutions that we had already discussed and explicitly rejected for stated reasons. This form of degradation is at least visible and can be corrected through repetition. More subtle and dangerous was conceptual drift, where the AI's understanding of project goals and constraints would gradually shift as early context providing the foundation for decisions faded while recent context that might represent specific exceptions dominated the model's attention. Most problematic was confident error, where the AI would make statements about earlier work or decisions with full apparent certainty that were actually incorrect, contradicting what had happened earlier in ways that could propagate errors if not caught through verification.
We managed context constraints through several strategies that others attempting similar projects might find useful to adopt. First and most importantly, we kept worker sessions focused on single bounded tasks and terminated them promptly upon completion. A worker implementing a single feature does not need to know the project's entire history or even most of it. It needs to understand its specific task from the issue description, know the relevant existing code that it will interface with, and follow the conventions documented in CLAUDE.md. By terminating workers after they complete their pull requests and cleaned up their branches, we avoided the context accumulation that degrades performance over long sessions. Each new worker started fresh with full context capacity available for its specific task, rather than inheriting accumulated baggage from previous work.
Second, we externalized project state to GitHub and the filesystem rather than relying on conversation memory. Issues recorded work to be done, their requirements, and their dependencies in a durable form that survived session boundaries. Pull requests recorded work completed, the changes made, and the rationale for decisions. Commits in the git history recorded every change with associated messages explaining what and why. The status.json file in the repository recorded which workers were active, what they were working on, and their current progress for the manager to reference. When a new session began, whether a new worker or a new manager session after handoff, it could reconstruct all necessary context by reading these external artifacts from the filesystem and GitHub API rather than relying on conversation history that did not persist.
Third, we documented project conventions in CLAUDE.md and related files that travel with the project repository. These instruction files are read early by any session working on the project, whether manager or worker. Any session that reads these files inherits accumulated knowledge about how the project should be built: what patterns to follow, what mistakes to avoid, what quality standards to maintain. This technique transforms ephemeral conversation context that would be lost at session end into persistent project knowledge that survives indefinitely and improves over time. When we learned something important about how the project should work through direct experience, we added it to CLAUDE.md rather than hoping any AI session would remember it from a conversation that might not persist to future sessions.
Fourth, we embraced session handoffs as a useful feature of the architecture rather than a limitation to work around reluctantly. When context becomes strained, manifesting as degraded response quality, forgotten information requiring repetition, or increased error rates, starting a fresh session with a clear summary of current state often produces better results than struggling forward with a degraded session trying to recover. The MANAGER_ROLE.md document includes explicit procedures for maintaining project stability before session handoffs, ensuring that the incoming session can pick up work smoothly. We learned to recognize the signs of context strain, including slower responses, questions about previously-covered topics, and inconsistency with earlier statements, and to proactively transition to fresh sessions before problems compounded rather than pushing through hoping performance would improve.
Fifth, we structured prompts to the AI to provide context efficiently rather than exhaustively. Rather than including lengthy explanations of project state in every message, we provided pointers to files that could be read on demand when that information was needed. Rather than repeating convention instructions in each task assignment, we referenced CLAUDE.md which the AI would read once at session start and retain in context. Rather than describing the current codebase state in prose, we asked the AI to read it directly from git status, issue lists, and file inspection. This demand-loading approach kept prompt sizes manageable while providing access to all necessary information when actually needed. The alternative of front-loading all potentially-relevant context would have consumed context capacity with information that might not be needed, leaving less capacity for the actual work.
Session Log Analysis: Real Metrics from Real Work
Theoretical discussion of development methodology is useful for understanding concepts, but concrete data from actual projects is necessary for calibrating expectations and making practical decisions. Our session logs provide detailed metrics about how this project actually developed, recording every message exchanged, every tool invoked, and every result returned. These logs can be analyzed to understand patterns in development activity that might not be obvious from final outputs alone.
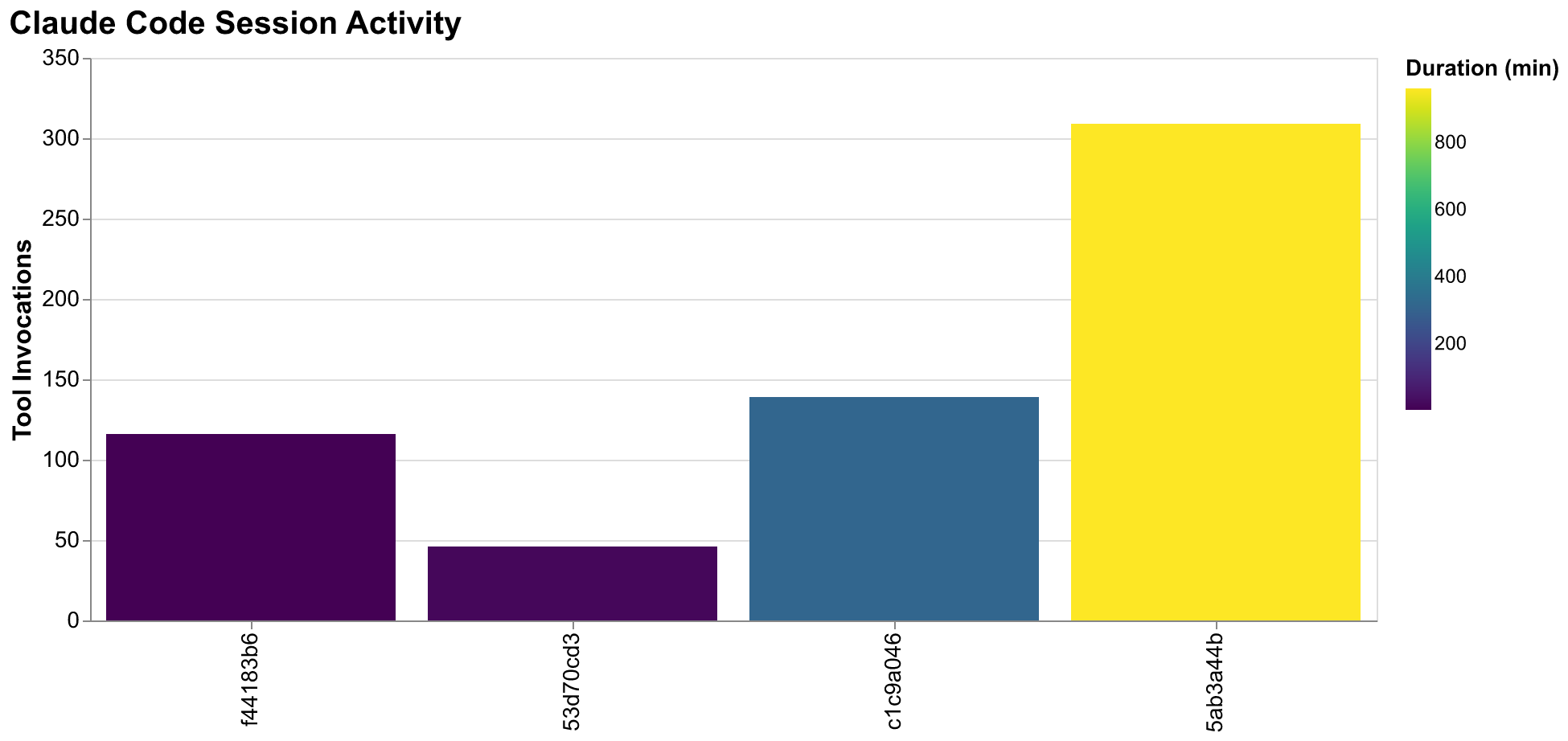
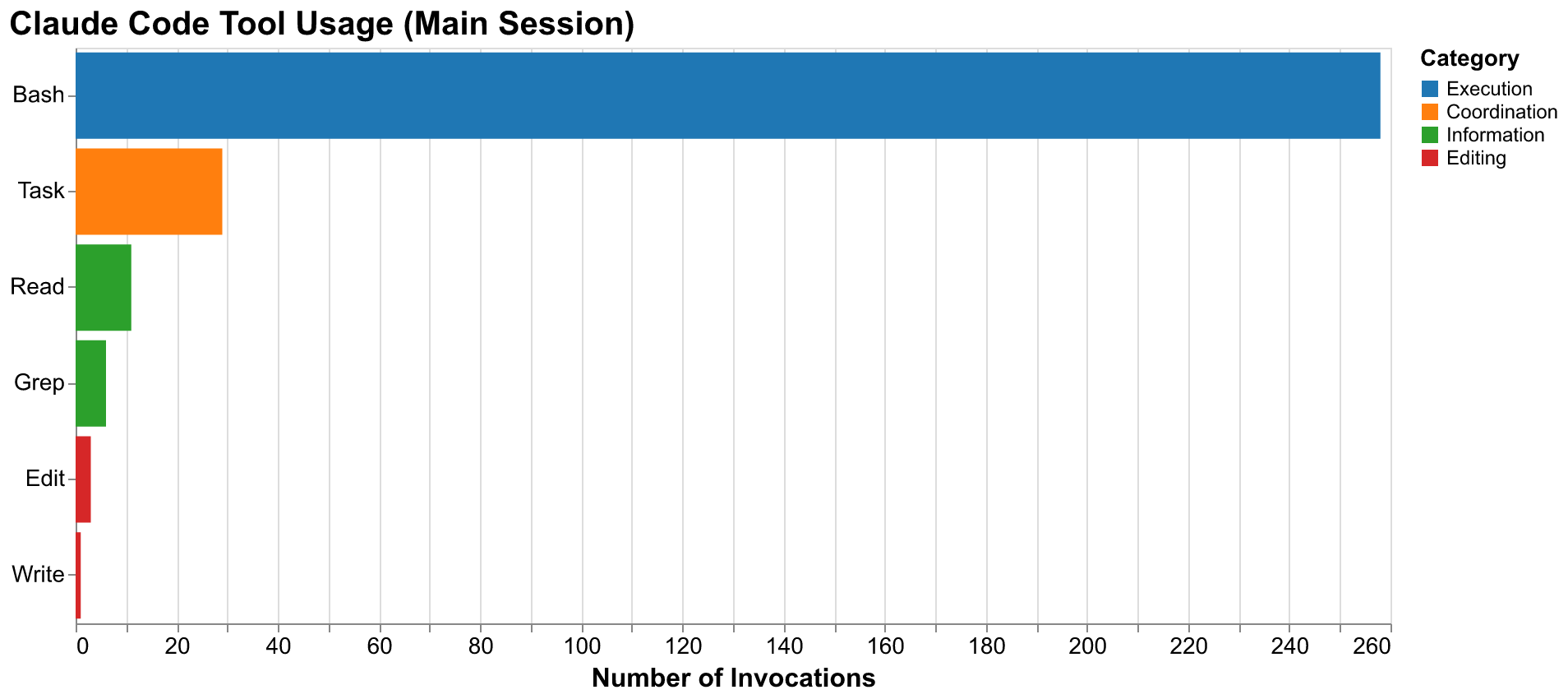
The project generated seven distinct session log files over its thirty-two hour duration, totaling 11,528 log lines across 161 MB of JSON-format data. The primary orchestration session where the manager role was executed (session ID 5ab3a44b) accumulated 10,285 log lines over approximately sixteen hours of active use spanning both development days. This session processed 709 distinct messages exchanged between human and AI, and invoked tools 309 times to perform concrete actions. The tool invocation breakdown is informative: 258 were Bash commands executing git operations, running tests, installing dependencies, or executing scripts; 29 were Task tool invocations spawning worker sessions for specific issues; 11 were Read operations examining file contents to understand existing code; 6 were Grep operations searching for patterns across the codebase; and the remainder were various other tools including Edit, Write, and Glob for file manipulation and discovery.
The session log file sizes reveal an interesting pattern about output volume management. The first substantial session (f44183b6) grew to 152 MB despite having only 116 tool calls across just two minutes of wall-clock time. This unexpected bloat resulted from an early attempt to spawn multiple parallel workers that generated large output streams from test execution and code generation. The verbose output from several workers running comprehensive test suites simultaneously overwhelmed the log before we implemented output truncation. This experience taught us to manage output volume more carefully. Subsequent sessions implemented truncation for large outputs and focused on summary information rather than full logs. The main orchestration session remained at 8.1 MB despite running for sixteen hours with three times the tool invocations, demonstrating that careful output management makes logs practical for analysis.
Worker session patterns tell their own story about task complexity and session duration. Session c1c9a046 ran for over five hours processing 105 messages and 139 tool calls, handling the bulk of initial project setup and several early feature implementations as we established patterns. The ratio of messages to tool calls in this session (105:139 = 0.76) indicates relatively high conversational density, suggesting substantial discussion, clarification, and iteration as we worked out how the project should be structured. Later worker sessions show lower ratios closer to 0.3-0.5, suggesting that established patterns enabled more efficient execution with less back-and-forth discussion once conventions were clear.
The message type distribution from our main orchestration session reveals the internal structure of AI-assisted development workflow. Of the logged events, 8,999 were "progress" markers tracking Bash command execution, 709 were substantive conversation messages with content, 352 were human input messages providing direction or feedback, 309 were tool invocation records, and 275 were "thinking" events where the AI processed complex requests requiring extended reasoning. The high ratio of progress events to substantive messages reflects the iterative nature of development: running a command, evaluating output, deciding on next steps, running another command. Each substantive message might trigger many progress events as its implications are worked through.
For readers wanting to analyze their own Claude Code session logs from their own machines, the following command will extract key metrics from recent sessions:
cd ~/.claude/projects
find . -name "*.jsonl" -mtime -7 | while read f; do
echo "## Session: $f"
echo "Lines: $(wc -l < "$f")"
echo "Size: $(du -h "$f" | cut -f1)"
echo "Tool calls: $(grep -c '"tool_use"' "$f" 2>/dev/null || echo 0)"
echo "User messages: $(grep -c '"type":"user"' "$f" 2>/dev/null || echo 0)"
echo "Assistant messages: $(grep -c '"type":"assistant"' "$f" 2>/dev/null || echo 0)"
echo "First entry: $(head -1 "$f" | jq -r '.sessionId // .timestamp' 2>/dev/null)"
echo "---"
done > ~/session-analysis.md && cat ~/session-analysis.mdThis command scans Claude Code session logs modified within the last seven days and extracts key metrics including line count, file size, tool invocations, and message counts. The output provides a summary of session activity that can inform decisions about session management strategies, identify patterns in one's own usage, and help diagnose performance issues if they arise. Running this analysis after completing a project reveals insights about how development time was actually spent versus how it felt subjectively during execution.
GitHub Integration: The Coordination Hub
GitHub served as the central nervous system of this project, providing the durable state and coordination mechanisms that made parallel AI-assisted development possible. Every piece of work flowed through GitHub's issue tracking and pull request systems. This was not merely a matter of following best practices or conforming to expected workflow; it was architecturally essential for coordinating parallel work streams and maintaining coherence across sessions that could not share context directly through conversation.
Issues defined work units with precision sufficient for independent implementation. Each GitHub issue created for this project contained several required components: detailed requirements explaining what capability or artifact needed to be created, acceptance criteria specifying exactly how completion would be determined without ambiguity, dependency lists noting which other issues must complete first before this work could begin, and context notes providing relevant background information or pointers to related code. When a worker session began, reading its assigned issue gave it everything needed to understand what was expected. This explicit specification served multiple functions. It prevented scope creep by constraining workers to their defined remit. It enabled objective completion assessment where either acceptance criteria were met or they were not. It provided the manager with clear status: work was either done or not done, not partially done in an ambiguous state. The discipline of writing precise issues paid dividends in reduced coordination overhead and clearer outcomes.
The project created 75 GitHub issues over its thirty-two hour duration, of which 57 are now closed indicating completed work and 18 remain open for future development beyond this sprint. Issue numbers ranged from #1 (initial project scaffolding) through #75 (process documentation capturing lessons learned). The issue density of approximately 2.3 issues created per hour reflects the granularity of our work decomposition. Smaller issues with focused scope were consistently easier to specify clearly, implement correctly, and verify thoroughly than larger issues that required more judgment calls and introduced more opportunities for misalignment between intent and execution.
Pull requests provided the integration and review mechanism that maintained quality despite rapid development and parallel execution. Each worker created a PR from its feature branch targeting main, with the description including the phrase "Closes #N" that triggers GitHub's automatic issue closure upon merge. PR descriptions followed a consistent template: summary of changes made in prose explaining the what and why, description of testing approach taken including what scenarios were covered, and notes about any concerns, assumptions, or decisions that reviewers should understand before approving. Claude's GitHub integration provided automated code review that ran on every PR, catching common issues including unused imports, type inconsistencies, style violations, and test failures before human review began. Human reviewers could then focus on higher-level concerns: correctness of logic and algorithms, alignment with architectural vision, appropriate handling of edge cases, and visual verification of any generated images or charts. Of the 27 PRs created during the sprint, all have been successfully merged following review.
GitHub Actions provided continuous integration infrastructure that caught problems automatically without requiring human attention until issues arose. Every PR triggered automated workflows including code formatting validation with ruff to ensure consistent style, type checking with pyright to catch type errors statically, and full test suite execution to verify that changes did not break existing functionality. These automated guardrails caught regressions within minutes of a PR opening, often before human review even began. When checks failed, the failure was visible in the PR status, and workers could address issues before requesting review. The automation freed human attention for concerns that required human judgment: reviewing algorithms for correctness, assessing architectural fit, and verifying visual outputs. Meanwhile, machines handled the mechanical verification that machines can perform more reliably and consistently than tired human reviewers.
Branch management provided isolation that allowed parallel work without interference. Each worker operated on a dedicated git branch named for its issue, either "issue-N" or a descriptive name when that was clearer. This isolation meant workers could make arbitrary changes to any files within their scope without affecting other workers' in-progress changes or the stable main branch. Workers never committed directly to main. All changes flowed through PRs that required passing checks and review. The manager monitored branch status through git commands and the GitHub API to understand work in progress at any time, and could intervene by messaging workers or adjusting subsequent work assignments if branches were diverging in ways that would create difficult merge conflicts.
What Worked: The Wins
Several aspects of this experiment exceeded our initial expectations significantly. Understanding these successes in specific terms helps identify where AI pair programming adds genuine value and provides guidance for when reaching for this approach makes sense.
Boilerplate generation was transformative in its impact on early project velocity when foundation work dominates. Setting up a new Python project properly involves numerous tedious tasks: creating directory hierarchies that match planned architecture, configuring pyproject.toml with dependencies, metadata, and build settings, setting up pytest configuration with appropriate options and fixtures, writing GitHub Actions workflows for CI and potentially CD, creating initial documentation structure with README, contributing guidelines, and license, and establishing code style configurations in ruff.toml or similar. This work typically takes hours of consulting tool documentation, copying and adapting templates from previous projects, and carefully verifying configuration options. Claude Code handled all of this in the first hour. The scaffolding was not merely minimal and adequate; it followed current best practices including pre-commit hooks for local quality enforcement and comprehensive CI workflows that would catch issues automatically. The project started from a professional foundation rather than a minimal skeleton that would require future hardening.
Consistency across a large codebase was remarkable and emerged without explicit enforcement mechanisms beyond pattern establishment. The visualization modules in this project, developed by different workers in separate sessions without direct communication, share common patterns throughout: consistent error handling that provides informative messages when things go wrong, uniform parameter naming that makes function signatures predictable, standardized documentation following Google docstring conventions, and similar structural organization within files. This consistency emerged naturally because Claude Code internalized patterns from the early examples it saw when reading existing code and applied those patterns to new code it created. Human developers working under similar time pressure would likely show more variation in style without explicit code review guidelines or automated enforcement. The resulting codebase is easier to navigate than many human-authored projects of comparable scope because readers can trust that patterns seen in one area will apply in others.
Essay drafting proved surprisingly effective, reshaping our understanding of AI capabilities in technical communication. We expected Claude Code to handle technical writing competently, producing functional documentation that conveyed necessary information in adequate prose. We were not prepared for its ability to weave engaging narrative around data analysis, to explain complex mathematical concepts accessibly without sacrificing accuracy, to maintain consistent voice and tone across multiple long-form pieces developed in separate sessions, and to structure persuasive arguments building from premises to conclusions. The essays in this project are not merely documentation; they are pieces we believe readers will find valuable and engaging. Human editing refined prose for style, caught occasional factual errors, and improved flow in places, but the fundamental structure, the content selected for inclusion, the arguments developed, and most of the actual sentences came from AI generation. This capability significantly expanded what we consider viable for AI to produce.
Parallel development enabled throughput that would be impossible for any number of individual developers working sequentially. While one worker implemented visualization infrastructure, another drafted the Roman Empire case study, a third built the forecasting pipeline, a fourth wrote an essay, and a fifth handled bug fixes from earlier work. This parallelism required careful coordination through our issue dependency system and occasionally created merge conflicts that needed resolution, but when managed properly through the manager-worker architecture, it effectively multiplied implementation throughput. At peak parallelism with five active workers, the project was accumulating implementation work at five times the rate any single developer could achieve regardless of skill or effort. The ceiling on parallelism was set by available independent work and coordination overhead, not by fundamental limitations of the approach.
The interactive explorer emerged from a single extended session, demonstrating AI's ability to work across technology boundaries fluently. What would typically require days of careful JavaScript development for the frontend, Python backend development for simulation, UI polish iterations with design review, and integration testing across the stack came together in hours. The explorer allows users to adjust model parameters through intuitive slider controls and immediately see simulations update with animated visualizations. It runs entirely in the browser using Pyodide for Python execution, requiring no backend server to deploy. Claude Code's ability to work across Python, JavaScript, HTML, and CSS in a single coherent implementation session, understanding how these pieces needed to fit together, enabled this rapid iteration without the context-switching overhead that slows human developers crossing technology boundaries.
What Did Not Work: The Struggles
Intellectual honesty requires acknowledging failures alongside successes. Several aspects of this experiment revealed limitations that future projects should anticipate and plan around rather than discovering through painful experience as we did.
Visual generation required extensive human intervention that we had not anticipated needing. AI systems can generate images and charts with remarkable fluency, producing outputs that superficially appear professional and complete. But they cannot reliably evaluate whether those outputs are actually correct according to the standards human observers would apply. We encountered numerous specific failure modes. Generated maps frequently had labels in wrong geographic positions, with city names placed in oceans or on the wrong continents entirely. Charts had distorted proportions that made visual comparison misleading, with scales varying unexpectedly between related visualizations. Animations had visual artifacts, sudden jumps, or confusing transitions that undermined rather than supported understanding. Text generated within images sometimes did not match the prompts provided, with labels missing, truncated, or altered in ways that changed meaning. Every visual asset in this project underwent human review before commit, and many required regeneration, often multiple times, to achieve acceptable quality. Our CLAUDE.md file now includes prominent warnings about visual verification because we learned through embarrassing early publications that this human review step is mandatory, not optional. The verification requirement creates a throughput bottleneck that limits how quickly visual-heavy content can be produced.

Chart sizing caused significant rework that could have been avoided with better upfront guardrails. Our initial Altair charts exported at wildly varying dimensions depending on data characteristics in ways that were not apparent during development but caused problems in production. One chart exported at 53,476 pixels in height, completely breaking browser rendering when the essay was viewed. The problem was that Altair's automatic sizing, which produces reasonable results for interactive exploration, behaved unexpectedly when exporting to static PNG files for embedding in documents. We implemented dimension validation only after discovering these problems with published content, adding issues #47 and #49 to address chart sizing systematically. The lesson is clear for future projects: AI-generated outputs need automated guardrails that catch problems mechanically, not just human review that might miss edge cases. Some failure modes are too subtle or too numerous for human reviewers to catch reliably, especially under time pressure.
Context loss caused subtle bugs that were difficult to diagnose because they did not manifest as obvious errors. When sessions ran long, earlier decisions, discussions, and constraints were sometimes forgotten despite remaining relevant. A worker might reintroduce a coding pattern we had explicitly rejected hours earlier, not from willful disregard but from genuine inability to access that earlier context. The manager session sometimes spawned work on issues already in progress by other workers, creating duplicate effort and potential merge conflicts, because context about active workers had faded. These failures were not individually catastrophic in the way that crashes or wrong outputs would be. But they accumulated into coordination overhead and rework that reduced effective throughput below what raw implementation speed would have suggested. The manager-worker architecture mitigated but did not eliminate these problems; longer manager sessions still accumulated context that eventually degraded performance.
Dependency management between parallel workers required more careful attention than our initial architecture anticipated. Worker A's PR might not merge before Worker B needed the changes it introduced, leading to either blocking waits that reduced parallelism or complex branch management where B based work on A's unmerged branch. Merge conflicts occurred when independent workers touched the same files, particularly shared resources like index.html that multiple essay workers needed to modify. The status.json tracking file and careful wave organization helped manage these problems but did not eliminate them. Our later process improvements documented in issues #71-75 emerged directly from coordination failures we experienced. Future projects should consider more sophisticated dependency tracking, perhaps with tooling that automatically detects potential conflicts before workers begin rather than at merge time.
Some generated content was simply wrong in ways that passed automated checks and superficial review. Claude Code occasionally produced code that executed successfully and passed tests yet violated requirements in subtle ways that only careful human review caught. Essays sometimes included claims that were not supported by project data, or that mischaracterized technical details in ways that an expert reader would notice. The AI's expressed confidence did not reliably correlate with actual correctness. High-confidence statements were sometimes wrong while hedged statements were sometimes accurate. Human review remained essential throughout for catching these failures, and even with review some errors likely escaped detection. We cannot know what problems we did not catch.
Lessons Learned: Process Improvements
The experiment generated concrete process improvements that we documented in GitHub issues #71 through #75 for the benefit of future work on this project and potentially other projects using similar approaches. These lessons emerged from direct experience with failures and represent hard-won knowledge that others might find valuable.
Visual planning should precede content creation, not follow it. Our CLAUDE.md file now mandates planning visualizations before drafting text for any visual-heavy content like essays. The requirement specifies: plan at least five illustrations, eight charts, and two animations before writing the first paragraph of prose. Generate the visual assets early in the process. Let the text flow around the visuals rather than trying to retrofit illustrations to completed prose. This ordering prevents a common failure mode where text is written describing analyses that should have supporting visuals, then visuals are created under pressure and either do not quite fit the text or require extensive revision to align. Planning visuals first also reveals scope clearly: if the planned visuals are too ambitious for the available time, that is visible before committing to text that depends on them.
Pre-commit validation should be automated wherever mechanical verification is possible. Rather than relying on human review to catch all problems, which is slow and error-prone especially for subtle issues, we added automated guardrails including dimension validation for chart outputs that rejects unreasonable sizes, file size limits for generated assets that flag unexpectedly large outputs, format validation for structured data files, and link checking for cross-references in documentation. Machines should catch machine-detectable errors automatically and reliably. Human review should then focus on aspects that genuinely require human judgment: whether the content is correct, whether it communicates effectively, whether it serves the intended purpose. Mixing mechanical verification with judgment-requiring review dilutes attention and allows both types of problems to slip through.
Worker task scoping requires explicit guidelines that prevent over-ambition. Issues should be completable within a single session with some headroom remaining for unexpected complications. If a task seems to require context accumulation across multiple sessions, or if its scope feels uncertain, it should be split into smaller issues before spawning a worker. The overhead of coordinating between multiple smaller tasks is consistently lower than the cost of context exhaustion occurring mid-task, which requires either abandoning partial work or attempting complex state reconstruction to resume. When workers fail, the root cause is almost always that their assigned tasks were too large or too vaguely specified, not that the tasks were too small or too tightly constrained.
Shared files need coordination protocols that prevent concurrent modification conflicts. Files like index.html that multiple workers might reasonably need to modify should have explicit ownership (only the manager modifies this file, incorporating changes from workers) or explicit merge planning (workers stage changes in comments that the manager integrates). Our merge conflict on day two of the project, commit 168d594 which resolved conflicting updates to the essay index from workers that did not know about each other, could have been avoided entirely with better protocols established upfront. The fix took only minutes, but the confusion and investigation consumed time that was better spent elsewhere. Coordination protocols add overhead but prevent problems that are more costly than the overhead.
Performance testing should precede user-facing feature deployment. The interactive explorer launched with noticeable lag on complex simulations that degraded user experience. We had not tested the feature under realistic parameter ranges and data volumes until it was deployed, at which point the performance problem was visible to users. Testing with representative workloads earlier in development would have revealed this problem when fixes were less disruptive. Any feature that users will interact with directly should have performance verification as a gate before deployment, not as a cleanup task after problems are reported.
The Economics of AI-Assisted Development
What does this experiment suggest about the economics of AI-assisted software development at this stage of the technology's maturity? The metrics we collected allow rough calculations that, while specific to this particular project, may inform thinking about similar efforts.
Traditional development estimates for work comparable in scope to what we produced might reasonably range from four to eight weeks for a skilled senior developer working full-time with focused attention. The scope comprises data integration with two external APIs requiring authentication and rate limiting, mathematical modeling with systems of coupled ODEs requiring numerical solver integration, parameter calibration using global optimization algorithms searching high-dimensional spaces, sophisticated visualization with three different libraries and multiple output formats, an interactive web application with real-time simulation and animated display, eight long-form essays totaling nearly 100,000 words of technical exposition, and comprehensive test coverage sufficient for confident modification. Any individual component here could reasonably fill a week of careful development. Together they represent substantial scope that a single developer would approach cautiously.
Our actual time was approximately thirty-two hours of active human engagement over two calendar days. This represents a compression factor of roughly ten to twenty times compared to traditional estimates, depending on how generous or conservative one makes those estimates. Even accounting for favorable conditions (unusually clear requirements, greenfield development without legacy constraints, concentrated attention without competing demands), the productivity gain compared to solo development is substantial. The code produced is not demo quality that would require extensive rework for production; it has tests, documentation, error handling, and production-grade structure throughout.
The cost structure differs from traditional development in ways worth noting. AI API usage incurs direct costs per token processed that traditional development does not have. Human time shifts from implementation, which is cheap for AI and expensive for humans, toward direction and verification, which require human judgment but involve less total time. Quality assurance requires different approaches, with automated guardrails becoming more important while human review shifts to higher-level concerns. These structural shifts favor projects where requirements are clear enough to specify precisely, where verification is tractable through testing and review, and where parallelism is possible because independent work exists. Projects lacking these characteristics will see smaller gains and may not benefit at all.
The economics are most favorable when several conditions hold simultaneously. Requirements should be clear enough that specification time is small relative to implementation time, reducing iteration costs. Patterns should be establishable early and reusable frequently, enabling accumulation rather than constant novel problem-solving. Verification should be automatable to a substantial degree, reducing the human bottleneck for quality assurance. Parallelism should be achievable because independent work exists that does not create coordination nightmares. Projects missing multiple of these characteristics will experience smaller productivity multipliers and may find the coordination overhead of AI collaboration not worth the implementation speedup.
Implications for Software Development Practice
What does this experiment suggest for broader software development practice beyond the specific domain of cliodynamics replication? Several implications seem worth considering, though they remain speculative pending more systematic evidence from diverse projects.
The value of clear requirements increases dramatically in AI-assisted development. When AI can implement well-specified requirements quickly and consistently, the bottleneck shifts upstream to requirement specification itself. Investing substantial time in precise, complete, unambiguous requirements yields direct productivity returns because each requirement can rapidly become working, tested code. Vague requirements that human developers might interpret charitably, using domain knowledge and experience to fill gaps, become sources of misalignment when AI implements them literally according to words on the page. The premium on requirement clarity grows significantly when AI handles implementation.
Architecture becomes more important relative to implementation in determining long-term value. If implementation cost is low, architectural decisions dominate value creation over time. The choice of patterns that will scale and adapt, the structure of modules that enables independent modification, the interfaces between components that allow substitution, and the data models underlying functionality that constrain future options, all matter more when changing implementation is cheap but changing architecture remains expensive. Organizations may find architects becoming more valuable as implementation becomes less differentiating.
Code review skills become critical quality gatekeepers. If substantially more code is AI-generated, whether during initial development or through maintenance contributions, human review becomes the primary mechanism for ensuring quality. Reviewers must catch subtle correctness issues that tests do not cover, architectural drift that accumulates across many small changes, and specification violations that the AI confidently implements. Review efficiency and effectiveness become competitive advantages for teams and organizations. Training developers to review effectively may become as important as training them to implement effectively.
Documentation becomes a first-class artifact deserving explicit investment. AI generates documentation readily when instructed and guided, but produces varying quality when left to defaults. Projects that specify documentation requirements explicitly, including what should be documented, at what level of detail, in what style, and for what audience, get comprehensive documentation that would be expensive to produce manually. Projects that do not specify requirements get inconsistent documentation that may or may not serve readers' needs. Making documentation expectations explicit becomes essential for consistent quality, rather than hoping developers will document appropriately based on professional judgment.
Testing strategies may need reconsideration given AI characteristics. AI generates tests that cover explicitly specified requirements comprehensively but may miss edge cases that human intuition would catch. Property-based testing that explores input spaces systematically, fuzzing that probes for unexpected behavior, and mutation testing that verifies tests actually catch bugs might usefully complement AI-generated test suites. Test strategy should account for AI's strengths in coverage of explicit cases and blindspots in unusual combinations and adversarial inputs.
Limitations and Caveats
Several important limitations constrain the generalizability of results from this single experiment. Readers considering applying similar approaches should evaluate how their specific situations differ from ours before expecting comparable outcomes.
This project benefited from exceptionally clear scope compared to most software projects. We knew precisely what cliodynamics replication required because Turchin's published work provided detailed templates for analysis, modeling, and presentation. We had reference implementations to compare against for validation. Projects with ambiguous requirements, undefined scope, or evolving understanding of what to build would face additional challenges in the specification iteration that our clear scope mostly avoided.
The human contributor possessed relevant technical expertise across all domains the project touched. Understanding mathematical modeling allowed effective direction of SDT implementation and calibration. Python development experience enabled confident review of generated code. Software architecture knowledge informed structural decisions. Web technology familiarity supported explorer development. A domain expert without software background, or a software expert without domain knowledge, might struggle to provide useful direction or verify outputs in areas outside their expertise. The collaboration works best when humans can evaluate AI outputs competently.
The project was greenfield without legacy constraints that most real-world projects face. No existing code constrained decisions about structure, patterns, or technologies. No existing users depended on stability, backward compatibility, or familiar interfaces. No existing team had accumulated opinions about how things should work. Brownfield projects integrating with existing codebases, maintaining established APIs, and coordinating with existing team members and processes face fundamentally different challenges that this experiment did not test.
Results may not transfer directly to other technology stacks, languages, or problem domains. Python is exceptionally well-represented in AI training data and has clear, consistent idioms that AI can learn. Mathematical and scientific computing are common topics in technical training data. Other technology stacks including embedded systems, legacy enterprise languages, and niche frameworks, or other application domains including real-time systems, safety-critical applications, and heavily regulated industries, might yield substantially different results.
The compressed timeline benefited from continuous availability that real projects often lack. We worked through two days with concentrated attention, minimal interruptions, and no competing priorities demanding context switches. Real projects typically face meetings, production incidents, organizational overhead, and attention fragmentation that would spread similar work over much longer calendar time with associated context-switching costs and coordination challenges between sessions.
Future Directions
This experiment suggests directions for future investigation, both for continued development of this specific project and for the broader research community working on AI-assisted software development.
Better context management tools would reduce the coordination overhead that constrained our effective throughput. Automated summarization that preserves essential information while discarding details that are no longer relevant, selective context loading that brings relevant information into working memory on demand, and improved state persistence that survives session boundaries more gracefully could all extend effective session duration and reduce the friction of handoffs. These capabilities represent product opportunities for development tool vendors.
Automated visual verification would address a major bottleneck we encountered. If AI systems could reliably evaluate their own visual outputs against specifications, identifying misplaced labels, distorted proportions, illegible text, and other common failures, human review could focus on subjective quality and communication effectiveness rather than error detection. Computer vision approaches trained specifically for chart and diagram verification represent a potentially valuable research direction.
More sophisticated dependency tracking between parallel workers could enable higher parallelism with fewer conflicts and coordination failures. Perhaps tooling could automatically analyze planned changes to detect potential merge conflicts before workers begin, or could suggest work orderings that minimize coordination overhead while maximizing parallelism. The manager-worker architecture we used has clear room for optimization with better tooling support.
Integration with additional development tools would expand AI's effective capabilities for complex tasks. Currently, Claude Code operates primarily through command-line tools and file manipulation. Richer integration with IDEs for semantic navigation and refactoring, with debuggers for interactive troubleshooting, and with profilers for performance analysis might enable development workflows that are currently awkward or impractical within the command-line paradigm.
Systematic studies across diverse projects would establish more reliable productivity estimates and identify which project characteristics predict success with AI-assisted approaches. This single experiment cannot establish generalizable rates or identify boundary conditions, but systematic data collection across many projects with controlled variations in scope, domain, team structure, and methodology could build the evidence base needed for confident planning decisions.
Conclusion: A Glimpse of the Future
This experiment offers a glimpse of software development's near-term future that we found surprising in its proximity to the present. AI pair programming is not a distant possibility requiring fundamental breakthroughs in artificial intelligence; it is a present capability with substantial benefits and known limitations available today. The thirty-two hours documented in this essay produced work that would have taken weeks or months through traditional solo development methods, while maintaining quality standards throughout.
But this technology is not a replacement for human judgment, and we should be clear-eyed about that limitation. Strategic direction still requires humans who understand what should be built and why it matters. Quality verification still requires humans who can assess whether outputs are correct and valuable. Architectural decisions still require humans who can evaluate tradeoffs that depend on context AI does not possess. The partnership between human direction and AI implementation is genuine: both contributions are essential, and neither can substitute for the other.
The cliodynamics project itself continues active development beyond the sprint documented here. This essay joins seven others in documenting our replication of Turchin's research on secular cycles and societal instability. The interactive explorer allows anyone to experiment with demographic-structural dynamics. The codebase provides a foundation for further research, extension, and perhaps eventual contribution to the scientific literature. What began as an experiment in AI-assisted development methodology became a genuine contribution to making cliodynamics accessible, which was the actual goal from the start.
We began this essay with a question: can AI pair programming actually work for substantial software projects? Based on the evidence from this experiment, the answer is yes, it can work, but with important caveats that determine when the approach is appropriate. It works when requirements are clear enough to specify without extensive iteration. It works when verification is possible through automated testing and structured human review. It works when humans remain engaged as directors of activity and verifiers of quality throughout the process. It struggles when outputs cannot be verified objectively, when context requirements exceed what sessions can maintain, and when ambiguity requires human judgment that cannot be articulated in advance.
For developers considering AI assistance for their own projects, this experiment suggests starting with small, bounded, clearly-specified tasks to build confidence in the collaboration model before attempting more ambitious undertakings. Invest early in tooling and processes that manage AI limitations proactively, including automated validation, context management, and review workflows, rather than discovering limitations reactively through failures. Most importantly, remain engaged throughout the process. The technology augments human capability powerfully but does not replace the need for human judgment, human verification, and human direction. The augmentation works best when humans stay actively in the loop, guiding AI capabilities toward valuable outcomes.
The future of software development, at least for a substantial class of projects, appears to be neither humans alone nor AI alone. It is humans with AI, each contributing their distinct strengths to collaborative creation. Humans contribute judgment, direction, verification, and the understanding of what is valuable. AI contributes implementation speed, consistency, breadth across technologies, and tireless execution of well-specified tasks. Together, this collaboration can produce results that neither could achieve working alone. This cliodynamics project stands as one concrete example of what that partnership can accomplish. We expect many more examples to emerge as tools mature, practices evolve, and the community learns collectively from shared experience. The experiment continues.